Execute this notebook:
![]()
![]() Download locally
Download locally
Node representation learning with GraphSAGE and UnsupervisedSampler¶
Stellargraph Unsupervised GraphSAGE is the implementation of GraphSAGE method outlined in the paper: Inductive Representation Learning on Large Graphs. W.L. Hamilton, R. Ying, and J. Leskovec arXiv:1706.02216 [cs.SI], 2017.
This notebook is a short demo of how Stellargraph Unsupervised GraphSAGE can be used to learn embeddings of the nodes representing papers in the CORA citation network. Furthermore, this notebook demonstrates the use of the learnt embeddings in a downstream node classification task (classifying papers by subject). Note that the node embeddings can also be used in other graph machine learning tasks, such as link prediction, community detection, etc.
Unsupervised GraphSAGE:¶
A high-level explanation of the unsupervised GraphSAGE method of graph representation learning is as follows.
Objective: Given a graph, learn embeddings of the nodes using only the graph structure and the node features, without using any known node class labels (hence “unsupervised”; for semi-supervised learning of node embeddings, see this demo)
Unsupervised GraphSAGE model: In the Unsupervised GraphSAGE model, node embeddings are learnt by solving a simple classification task: given a large set of “positive” (target, context) node pairs generated from random walks performed on the graph (i.e., node pairs that co-occur within a certain context window in random walks), and an equally large set of “negative” node pairs that are randomly selected from the graph according to a certain distribution, learn a binary classifier that
predicts whether arbitrary node pairs are likely to co-occur in a random walk performed on the graph. Through learning this simple binary node-pair-classification task, the model automatically learns an inductive mapping from attributes of nodes and their neighbors to node embeddings in a high-dimensional vector space, which preserves structural and feature similarities of the nodes. Unlike embeddings obtained by algorithms such as Node2Vec, this mapping
is inductive: given a new node (with attributes) and its links to other nodes in the graph (which was unseen during model training), we can evaluate its embeddings without having to re-train the model.
In our implementation of Unsupervised GraphSAGE, the training set of node pairs is composed of an equal number of positive and negative (target, context) pairs from the graph. The positive (target, context) pairs are the node pairs co-occurring on random walks over the graph whereas the negative node pairs are sampled randomly from a global node degree distribution of the graph.
The architecture of the node pair classifier is the following. Input node pairs (with node features) are fed, together with the graph structure, into a pair of identical GraphSAGE encoders, producing a pair of node embeddings. These embeddings are then fed into a node pair classification layer, which applies a binary operator to those node embeddings (e.g., concatenating them), and passes the resulting node pair embeddings through a linear transform followed by a binary activation (e.g., sigmoid), thus predicting a binary label for the node pair.
The entire model is trained end-to-end by minimizing the loss function of choice (e.g., binary cross-entropy between predicted node pair labels and true link labels) using stochastic gradient descent (SGD) updates of the model parameters, with minibatches of ‘training’ links generated on demand and fed into the model.
Node embeddings obtained from the encoder part of the trained classifier can be used in various downstream tasks. In this demo, we show how these can be used for predicting node labels.
[3]:
import networkx as nx
import pandas as pd
import numpy as np
import os
import random
import stellargraph as sg
from stellargraph.data import EdgeSplitter
from stellargraph.mapper import GraphSAGELinkGenerator
from stellargraph.layer import GraphSAGE, link_classification
from stellargraph.data import UniformRandomWalk
from stellargraph.data import UnsupervisedSampler
from sklearn.model_selection import train_test_split
from tensorflow import keras
from sklearn import preprocessing, feature_extraction, model_selection
from sklearn.linear_model import LogisticRegressionCV, LogisticRegression
from sklearn.metrics import accuracy_score
from stellargraph import globalvar
from stellargraph import datasets
from IPython.display import display, HTML
Loading the CORA network data¶
(See the “Loading from Pandas” demo for details on how data can be loaded.)
[4]:
dataset = datasets.Cora()
display(HTML(dataset.description))
G, node_subjects = dataset.load()
[5]:
print(G.info())
StellarGraph: Undirected multigraph
Nodes: 2708, Edges: 5429
Node types:
paper: [2708]
Edge types: paper-cites->paper
Edge types:
paper-cites->paper: [5429]
Unsupervised GraphSAGE with on demand sampling¶
The Unsupervised GraphSAGE requires a training sample that can be either provided as a list of (target, context) node pairs or it can be provided with an UnsupervisedSampler instance that takes care of generating positive and negative samples of node pairs on demand. In this demo we discuss the latter technique.
UnsupervisedSampler:¶
The UnsupervisedSampler class takes in a Stellargraph graph instance. The generator method in the UnsupervisedSampler is responsible for generating equal number of positive and negative node pair samples from the graph for training. The samples are generated by performing uniform random walks over the graph, using UniformRandomWalk object. Positive (target, context) node pairs are extracted from the walks, and for each positive pair a corresponding negative pair
(target, node) is generated by randomly sampling node from the degree distribution of the graph. Once the batch_size number of samples is accumulated, the generator yields a list of positive and negative node pairs along with their respective 1/0 labels.
In the current implementation, we use uniform random walks to explore the graph structure. The length and number of walks, as well as the root nodes for starting the walks can be user-specified. The default list for root nodes is all nodes of the graph, default number_of_walks is 1 (at least one walk per root node), and the default length of walks is 2 (need at least one node beyond the root node on the walk as a potential positive context).
1. Specify the other optional parameter values: root nodes, the number of walks to take per node, the length of each walk, and random seed.
[6]:
nodes = list(G.nodes())
number_of_walks = 1
length = 5
2. Create the UnsupervisedSampler instance with the relevant parameters passed to it.
[7]:
unsupervised_samples = UnsupervisedSampler(
G, nodes=nodes, length=length, number_of_walks=number_of_walks
)
The graph G together with the unsupervised sampler will be used to generate samples.
3. Create a node pair generator:
Next, create the node pair generator for sampling and streaming the training data to the model. The node pair generator essentially “maps” pairs of nodes (target, context) to the input of GraphSAGE: it either takes minibatches of node pairs, or an UnsupervisedSampler instance which generates the minibatches of node pairs on demand. The generator samples 2-hop subgraphs with (target, context) head nodes extracted from those pairs, and feeds them, together with the corresponding binary
labels indicating which pair represent positive or negative sample, to the input layer of the node pair classifier with GraphSAGE node encoder, for SGD updates of the model parameters.
Specify: 1. The minibatch size (number of node pairs per minibatch). 2. The number of epochs for training the model. 3. The sizes of 1- and 2-hop neighbor samples for GraphSAGE:
Note that the length of num_samples list defines the number of layers/iterations in the GraphSAGE encoder. In this example, we are defining a 2-layer GraphSAGE encoder.
[8]:
batch_size = 50
epochs = 4
num_samples = [10, 5]
In the following we show the working of node pair generator with the UnsupervisedSampler, which will generate samples on demand.
[9]:
generator = GraphSAGELinkGenerator(G, batch_size, num_samples)
train_gen = generator.flow(unsupervised_samples)
Build the model: a 2-layer GraphSAGE encoder acting as node representation learner, with a link classification layer on concatenated (citing-paper, cited-paper) node embeddings.
GraphSAGE part of the model, with hidden layer sizes of 50 for both GraphSAGE layers, a bias term, and no dropout. (Dropout can be switched on by specifying a positive dropout rate, 0 < dropout < 1). Note that the length of layer_sizes list must be equal to the length of num_samples, as len(num_samples) defines the number of hops (layers) in the GraphSAGE encoder.
[10]:
layer_sizes = [50, 50]
graphsage = GraphSAGE(
layer_sizes=layer_sizes, generator=generator, bias=True, dropout=0.0, normalize="l2"
)
[11]:
# Build the model and expose input and output sockets of graphsage, for node pair inputs:
x_inp, x_out = graphsage.in_out_tensors()
Final node pair classification layer that takes a pair of nodes’ embeddings produced by graphsage encoder, applies a binary operator to them to produce the corresponding node pair embedding (ip for inner product; other options for the binary operator can be seen by running a cell with ?link_classification in it), and passes it through a dense layer:
[12]:
prediction = link_classification(
output_dim=1, output_act="sigmoid", edge_embedding_method="ip"
)(x_out)
link_classification: using 'ip' method to combine node embeddings into edge embeddings
Stack the GraphSAGE encoder and prediction layer into a Keras model, and specify the loss
[13]:
model = keras.Model(inputs=x_inp, outputs=prediction)
model.compile(
optimizer=keras.optimizers.Adam(lr=1e-3),
loss=keras.losses.binary_crossentropy,
metrics=[keras.metrics.binary_accuracy],
)
4. Train the model.
[14]:
history = model.fit(
train_gen,
epochs=epochs,
verbose=1,
use_multiprocessing=False,
workers=4,
shuffle=True,
)
Epoch 1/4
434/434 [==============================] - 35s 80ms/step - loss: 0.5668 - binary_accuracy: 0.7413
Epoch 2/4
434/434 [==============================] - 33s 77ms/step - loss: 0.5404 - binary_accuracy: 0.7739
Epoch 3/4
434/434 [==============================] - 34s 78ms/step - loss: 0.5378 - binary_accuracy: 0.7823
Epoch 4/4
434/434 [==============================] - 34s 78ms/step - loss: 0.5383 - binary_accuracy: 0.7815
Note that multiprocessing is switched off, since with a large training set of node pairs, multiprocessing can considerably slow down the training process with the data being transferred between various processes.
Also, multiple workers can be used with Keras version 2.2.4 and above, and it speeds up the training process considerably due to multi-threading.
Extracting node embeddings¶
Now that the node pair classifier is trained, we can use its node encoder part as node embeddings evaluator. Below we evaluate node embeddings as activations of the output of GraphSAGE layer stack, and visualise them, coloring nodes by their subject label.
[15]:
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
from stellargraph.mapper import GraphSAGENodeGenerator
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
Building a new node-based model
The (src, dst) node pair classifier model has two identical node encoders: one for source nodes in the node pairs, the other for destination nodes in the node pairs passed to the model. We can use either of the two identical encoders to evaluate node embeddings. Below we create an embedding model by defining a new Keras model with x_inp_src (a list of odd elements in x_inp) and x_out_src (the 1st element in x_out) as input and output, respectively. Note that this model’s
weights are the same as those of the corresponding node encoder in the previously trained node pair classifier.
[16]:
x_inp_src = x_inp[0::2]
x_out_src = x_out[0]
embedding_model = keras.Model(inputs=x_inp_src, outputs=x_out_src)
We also need a node generator to feed graph nodes to embedding_model. We want to evaluate node embeddings for all nodes in the graph:
[17]:
node_ids = node_subjects.index
node_gen = GraphSAGENodeGenerator(G, batch_size, num_samples).flow(node_ids)
We now use node_gen to feed all nodes into the embedding model and extract their embeddings:
[18]:
node_embeddings = embedding_model.predict(node_gen, workers=4, verbose=1)
55/55 [==============================] - 1s 19ms/step
Visualize the node embeddings¶
Next we visualize the node embeddings in 2D using t-SNE. Colors of the nodes depict their true classes (subject in the case of Cora dataset) of the nodes.
[19]:
node_subject = node_subjects.astype("category").cat.codes
X = node_embeddings
if X.shape[1] > 2:
transform = TSNE # PCA
trans = transform(n_components=2)
emb_transformed = pd.DataFrame(trans.fit_transform(X), index=node_ids)
emb_transformed["label"] = node_subject
else:
emb_transformed = pd.DataFrame(X, index=node_ids)
emb_transformed = emb_transformed.rename(columns={"0": 0, "1": 1})
emb_transformed["label"] = node_subject
[20]:
alpha = 0.7
fig, ax = plt.subplots(figsize=(7, 7))
ax.scatter(
emb_transformed[0],
emb_transformed[1],
c=emb_transformed["label"].astype("category"),
cmap="jet",
alpha=alpha,
)
ax.set(aspect="equal", xlabel="$X_1$", ylabel="$X_2$")
plt.title(
"{} visualization of GraphSAGE embeddings for cora dataset".format(transform.__name__)
)
plt.show()
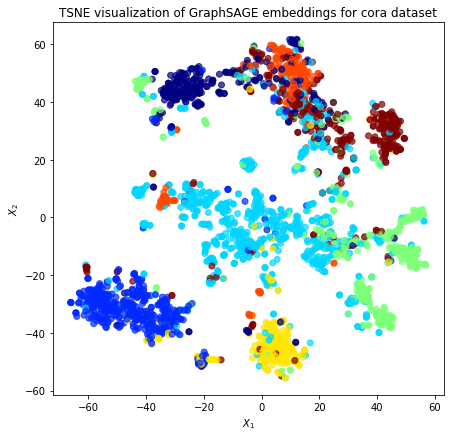
The observation that same-colored nodes in the embedding space are concentrated together is indicative of similarity of embeddings of papers on the same topics. We would emphasize here again that the node embeddings are learnt in unsupervised way, without using true class labels.
Downstream task¶
The node embeddings calculated using the unsupervised GraphSAGE can be used as node feature vectors in a downstream task such as node classification.
In this example, we will use the node embeddings to train a simple Logistic Regression classifier to predict paper subjects in Cora dataset.
[21]:
# X will hold the 50 input features (node embeddings)
X = node_embeddings
# y holds the corresponding target values
y = np.array(node_subject)
Data Splitting¶
We split the data into train and test sets.
We use 5% of the data for training and the remaining 95% for testing as a hold out test set.
[22]:
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=0.05, test_size=None, stratify=y
)
Classifier Training¶
We train a Logistic Regression classifier on the training data.
[23]:
clf = LogisticRegression(verbose=0, solver="lbfgs", multi_class="auto")
clf.fit(X_train, y_train)
[23]:
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
Predict the hold out test set.
[24]:
y_pred = clf.predict(X_test)
Calculate the accuracy of the classifier on the test set.
[25]:
accuracy_score(y_test, y_pred)
[25]:
0.7427127866303925
The obtained accuracy is pretty decent, better than that obtained by using node embeddings obtained by node2vec that ignores node attributes, only taking into account the graph structure (see this demo).
Predicted classes
[26]:
pd.Series(y_pred).value_counts()
[26]:
2 831
1 428
6 406
3 356
0 334
4 195
5 23
dtype: int64
True classes
[27]:
pd.Series(y).value_counts()
[27]:
2 818
3 426
1 418
6 351
0 298
4 217
5 180
dtype: int64
Uses for unsupervised graph representation learning¶
Unsupervised GraphSAGE learns embeddings of unlabeled graph nodes. This is highly useful as most of the real-world data is typically either unlabeled, or have noisy, unreliable, or sparse labels. In such scenarios unsupervised techniques that learn low-dimensional meaningful representation of nodes in a graph by leveraging the graph structure and features of the nodes is useful.
Moreover, GraphSAGE is an inductive technique that allows us to obtain embeddings of unseen nodes, without the need to re-train the embedding model. That is, instead of training individual embeddings for each node (as in algorithms such as
node2vecthat learn a look-up table of node embeddings), GraphSAGE learns a function that generates embeddings by sampling and aggregating attributes from each node’s local neighborhood, and combining those with the node’s own attributes.
Execute this notebook:
![]()
![]() Download locally
Download locally
