Execute this notebook:
![]()
![]() Download locally
Download locally
Node classification with directed GraphSAGE¶
This example shows the application of directed GraphSAGE to a directed graph, where the in-node and out-node neighbourhoods are separately sampled and have different weights.
Import stellargraph:
[3]:
import pandas as pd
import os
import stellargraph as sg
from stellargraph.mapper import DirectedGraphSAGENodeGenerator
from stellargraph.layer import DirectedGraphSAGE
from tensorflow.keras import layers, optimizers, losses, metrics, Model
from sklearn import preprocessing, feature_extraction, model_selection
from stellargraph import datasets
from IPython.display import display, HTML
import matplotlib.pyplot as plt
%matplotlib inline
Loading the CORA network¶
(See the “Loading from Pandas” demo for details on how data can be loaded.)
[4]:
dataset = datasets.Cora()
display(HTML(dataset.description))
G, node_subjects = dataset.load(directed=True)
[5]:
print(G.info())
StellarDiGraph: Directed multigraph
Nodes: 2708, Edges: 5429
Node types:
paper: [2708]
Edge types: paper-cites->paper
Edge types:
paper-cites->paper: [5429]
We aim to train a graph-ML model that will predict the “subject” attribute on the nodes. These subjects are one of 7 categories:
[6]:
set(node_subjects)
[6]:
{'Case_Based',
'Genetic_Algorithms',
'Neural_Networks',
'Probabilistic_Methods',
'Reinforcement_Learning',
'Rule_Learning',
'Theory'}
Splitting the data¶
For machine learning we want to take a subset of the nodes for training, and use the rest for testing. We’ll use scikit-learn again to do this
[7]:
train_subjects, test_subjects = model_selection.train_test_split(
node_subjects, train_size=0.1, test_size=None, stratify=node_subjects
)
Note using stratified sampling gives the following counts:
[8]:
from collections import Counter
Counter(train_subjects)
[8]:
Counter({'Probabilistic_Methods': 42,
'Genetic_Algorithms': 42,
'Neural_Networks': 81,
'Case_Based': 30,
'Theory': 35,
'Reinforcement_Learning': 22,
'Rule_Learning': 18})
The training set has class imbalance that might need to be compensated, e.g., via using a weighted cross-entropy loss in model training, with class weights inversely proportional to class support. However, we will ignore the class imbalance in this example, for simplicity.
Converting to numeric arrays¶
For our categorical target, we will use one-hot vectors that will be fed into a soft-max Keras layer during training. To do this conversion …
[9]:
target_encoding = preprocessing.LabelBinarizer()
train_targets = target_encoding.fit_transform(train_subjects)
test_targets = target_encoding.transform(test_subjects)
We now do the same for the node attributes we want to use to predict the subject. These are the feature vectors that the Keras model will use as input. The CORA dataset contains attributes ‘w_x’ that correspond to words found in that publication. If a word occurs more than once in a publication the relevant attribute will be set to one, otherwise it will be zero.
Creating the GraphSAGE model in Keras¶
To feed data from the graph to the Keras model we need a data generator that feeds data from the graph to the model. The generators are specialized to the model and the learning task so we choose the DirectedGraphSAGENodeGenerator as we are predicting node attributes with a DirectedGraphSAGE model.
We need two other parameters, the batch_size to use for training and the number of nodes to sample at each level of the model. Here we choose a two-level model with 10 nodes sampled in the first layer (5 in-nodes and 5 out-nodes), and 4 in the second layer (2 in-nodes and 2 out-nodes).
[10]:
batch_size = 50
in_samples = [5, 2]
out_samples = [5, 2]
A DirectedGraphSAGENodeGenerator object is required to send the node features in sampled subgraphs to Keras
[11]:
generator = DirectedGraphSAGENodeGenerator(G, batch_size, in_samples, out_samples)
Using the generator.flow() method, we can create iterators over nodes that should be used to train, validate, or evaluate the model. For training we use only the training nodes returned from our splitter and the target values. The shuffle=True argument is given to the flow method to improve training.
[12]:
train_gen = generator.flow(train_subjects.index, train_targets, shuffle=True)
Now we can specify our machine learning model, we need a few more parameters for this:
the
layer_sizesis a list of hidden feature sizes of each layer in the model. In this example we use 32-dimensional hidden node features at each layer, which corresponds to 12 weights for each head node, 10 for each in-node and 10 for each out-node.The
biasanddropoutare internal parameters of the model.
[13]:
graphsage_model = DirectedGraphSAGE(
layer_sizes=[32, 32], generator=generator, bias=False, dropout=0.5,
)
Now we create a model to predict the 7 categories using Keras softmax layers.
[14]:
x_inp, x_out = graphsage_model.in_out_tensors()
prediction = layers.Dense(units=train_targets.shape[1], activation="softmax")(x_out)
Training the model¶
Now let’s create the actual Keras model with the graph inputs x_inp provided by the graph_model and outputs being the predictions from the softmax layer
[15]:
model = Model(inputs=x_inp, outputs=prediction)
model.compile(
optimizer=optimizers.Adam(lr=0.005),
loss=losses.categorical_crossentropy,
metrics=["acc"],
)
Train the model, keeping track of its loss and accuracy on the training set, and its generalisation performance on the test set (we need to create another generator over the test data for this)
[16]:
test_gen = generator.flow(test_subjects.index, test_targets)
[17]:
history = model.fit(
train_gen, epochs=20, validation_data=test_gen, verbose=2, shuffle=False
)
Epoch 1/20
6/6 - 3s - loss: 1.9108 - acc: 0.2037 - val_loss: 1.7470 - val_acc: 0.4208
Epoch 2/20
6/6 - 3s - loss: 1.6590 - acc: 0.4741 - val_loss: 1.6306 - val_acc: 0.5033
Epoch 3/20
6/6 - 3s - loss: 1.5334 - acc: 0.6407 - val_loss: 1.5296 - val_acc: 0.5747
Epoch 4/20
6/6 - 3s - loss: 1.4189 - acc: 0.7111 - val_loss: 1.4301 - val_acc: 0.6427
Epoch 5/20
6/6 - 3s - loss: 1.2873 - acc: 0.8222 - val_loss: 1.3533 - val_acc: 0.6887
Epoch 6/20
6/6 - 3s - loss: 1.1953 - acc: 0.8778 - val_loss: 1.2833 - val_acc: 0.6998
Epoch 7/20
6/6 - 3s - loss: 1.1191 - acc: 0.8704 - val_loss: 1.2165 - val_acc: 0.7125
Epoch 8/20
6/6 - 3s - loss: 1.0075 - acc: 0.9037 - val_loss: 1.1577 - val_acc: 0.7285
Epoch 9/20
6/6 - 3s - loss: 0.9367 - acc: 0.9333 - val_loss: 1.1151 - val_acc: 0.7301
Epoch 10/20
6/6 - 3s - loss: 0.8731 - acc: 0.9074 - val_loss: 1.0749 - val_acc: 0.7379
Epoch 11/20
6/6 - 4s - loss: 0.8125 - acc: 0.9519 - val_loss: 1.0341 - val_acc: 0.7465
Epoch 12/20
6/6 - 3s - loss: 0.7387 - acc: 0.9630 - val_loss: 0.9955 - val_acc: 0.7523
Epoch 13/20
6/6 - 3s - loss: 0.6990 - acc: 0.9519 - val_loss: 0.9530 - val_acc: 0.7596
Epoch 14/20
6/6 - 3s - loss: 0.6277 - acc: 0.9519 - val_loss: 0.9260 - val_acc: 0.7600
Epoch 15/20
6/6 - 3s - loss: 0.5893 - acc: 0.9704 - val_loss: 0.9063 - val_acc: 0.7683
Epoch 16/20
6/6 - 3s - loss: 0.5596 - acc: 0.9667 - val_loss: 0.8913 - val_acc: 0.7728
Epoch 17/20
6/6 - 3s - loss: 0.5042 - acc: 0.9889 - val_loss: 0.8663 - val_acc: 0.7678
Epoch 18/20
6/6 - 3s - loss: 0.4836 - acc: 0.9741 - val_loss: 0.8455 - val_acc: 0.7793
Epoch 19/20
6/6 - 3s - loss: 0.4544 - acc: 0.9778 - val_loss: 0.8271 - val_acc: 0.7789
Epoch 20/20
6/6 - 3s - loss: 0.4048 - acc: 0.9926 - val_loss: 0.8010 - val_acc: 0.7888
[18]:
sg.utils.plot_history(history)
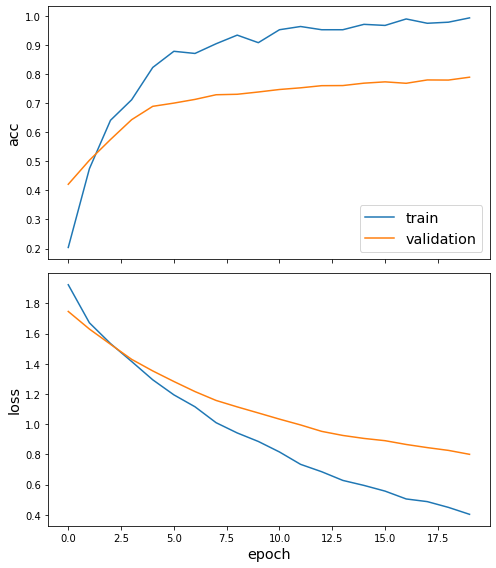
Now we have trained the model we can evaluate on the test set.
[19]:
test_metrics = model.evaluate(test_gen)
print("\nTest Set Metrics:")
for name, val in zip(model.metrics_names, test_metrics):
print("\t{}: {:0.4f}".format(name, val))
Test Set Metrics:
loss: 0.8111
acc: 0.7830
Making predictions with the model¶
Now let’s get the predictions themselves for all nodes using another node iterator:
[20]:
all_nodes = node_subjects.index
all_mapper = generator.flow(all_nodes)
all_predictions = model.predict(all_mapper)
These predictions will be the output of the softmax layer, so to get final categories we’ll use the inverse_transform method of our target attribute specification to turn these values back to the original categories
[21]:
node_predictions = target_encoding.inverse_transform(all_predictions)
Let’s have a look at a few:
[22]:
df = pd.DataFrame({"Predicted": node_predictions, "True": node_subjects})
df.head(10)
[22]:
| Predicted | True | |
|---|---|---|
| 31336 | Theory | Neural_Networks |
| 1061127 | Rule_Learning | Rule_Learning |
| 1106406 | Reinforcement_Learning | Reinforcement_Learning |
| 13195 | Reinforcement_Learning | Reinforcement_Learning |
| 37879 | Probabilistic_Methods | Probabilistic_Methods |
| 1126012 | Probabilistic_Methods | Probabilistic_Methods |
| 1107140 | Theory | Theory |
| 1102850 | Theory | Neural_Networks |
| 31349 | Theory | Neural_Networks |
| 1106418 | Theory | Theory |
Node embeddings¶
Evaluate node embeddings as activations of the output of GraphSAGE layer stack, and visualise them, coloring nodes by their subject label.
The GraphSAGE embeddings are the output of the GraphSAGE layers, namely the x_out variable. Let’s create a new model with the same inputs as we used previously x_inp but now the output is the embeddings rather than the predicted class. Additionally note that the weights trained previously are kept in the new model.
[23]:
embedding_model = Model(inputs=x_inp, outputs=x_out)
[24]:
emb = embedding_model.predict(all_mapper)
emb.shape
[24]:
(2708, 32)
Project the embeddings to 2d using either TSNE or PCA transform, and visualise, coloring nodes by their subject label
[25]:
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
import pandas as pd
import numpy as np
[26]:
X = emb
y = np.argmax(target_encoding.transform(node_subjects), axis=1)
[27]:
if X.shape[1] > 2:
transform = TSNE # PCA
trans = transform(n_components=2)
emb_transformed = pd.DataFrame(trans.fit_transform(X), index=node_subjects.index)
emb_transformed["label"] = y
else:
emb_transformed = pd.DataFrame(X, index=node_subjects.index)
emb_transformed = emb_transformed.rename(columns={"0": 0, "1": 1})
emb_transformed["label"] = y
[28]:
alpha = 0.7
fig, ax = plt.subplots(figsize=(7, 7))
ax.scatter(
emb_transformed[0],
emb_transformed[1],
c=emb_transformed["label"].astype("category"),
cmap="jet",
alpha=alpha,
)
ax.set(aspect="equal", xlabel="$X_1$", ylabel="$X_2$")
plt.title(
"{} visualization of GraphSAGE embeddings for cora dataset".format(transform.__name__)
)
plt.show()
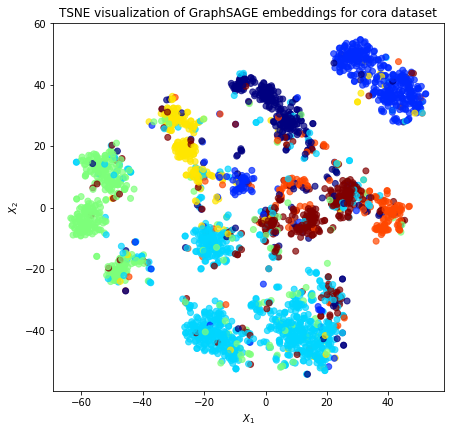
Observe that each class of paper is separated into three general regions. This is due to the fact that the GraphSAGE features from the previous layer for the node itself, the aggregated in-neighbours, and the aggregated out-neighbours are currently concatenated in the form [node, in_agg, out_agg].
There are four distinct types of directed neighbourhoods, namely: * Both in-neighbours and out-neighbours; * Only in-neighbours – in this case out_agg will be zero; * Only out-neighbours – in this case in_agg will be zero; * No in-neighbours or out-neighbours – in this case both in_agg and out_agg will be zero.
The fourth case, isolated nodes having no in-neighbours and no out-neighbours, does not occur for the CORA dataset (see the counts below) therefore the CORA dataset consists of the three types.
[29]:
directed_neigh_type = [
1 * (len(G.in_nodes(node)) > 0) + 2 * (len(G.out_nodes(node)) > 0)
for node in node_subjects.index
]
print(f"{sum(nt==0 for nt in directed_neigh_type)} nodes have no in or out neighbours")
print(f"{sum(nt==1 for nt in directed_neigh_type)} nodes have in but not out neighbours")
print(f"{sum(nt==2 for nt in directed_neigh_type)} nodes have out but no in neighbours")
print(f"{sum(nt==3 for nt in directed_neigh_type)} nodes have in and out neighbours")
0 nodes have no in or out neighbours
486 nodes have in but not out neighbours
1143 nodes have out but no in neighbours
1079 nodes have in and out neighbours
We visualize the clustering of these different directed neighbourhood types below:
[30]:
alpha = 0.7
fig, ax = plt.subplots(figsize=(7, 7))
ax.scatter(
emb_transformed[0], emb_transformed[1], c=directed_neigh_type, cmap="jet", alpha=alpha
)
ax.set(aspect="equal", xlabel="$X_1$", ylabel="$X_2$")
plt.title(
"{} visualization of GraphSAGE embeddings for cora dataset".format(transform.__name__)
)
plt.show()
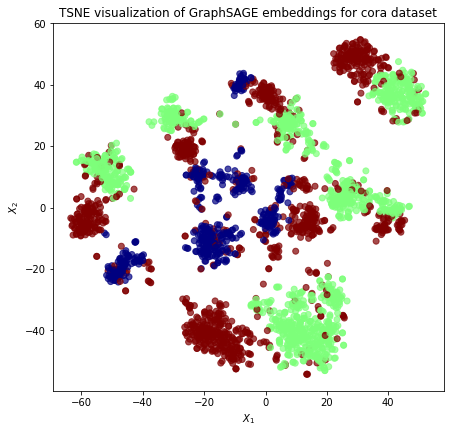
We note that we can reduce the splitting effect of these different directed neighbourhood types by adding the aggregated in-neighbourhood and out-neighbourhood rather that concatenating them. This feature is planned to be implemented soon.
Execute this notebook:
![]()
![]() Download locally
Download locally
