Execute this notebook:
![]()
![]() Download locally
Download locally
GraphSAGE with Neo4j¶
This example shows the application of GraphSAGE on the Cora dataset stored in Neo4j.
Subgraphs are sampled directly from Neo4j, which eliminate the need to store the whole graph structure in NetworkX. In this demo, node features are cached in memory for faster access since the dataset is relatively small.
[3]:
import pandas as pd
import os
import stellargraph as sg
from stellargraph.connector.neo4j import Neo4jGraphSAGENodeGenerator, Neo4jStellarGraph
from stellargraph.layer import GraphSAGE
import numpy as np
from tensorflow.keras import layers, optimizers, losses, metrics, Model
from sklearn import preprocessing, feature_extraction, model_selection
import time
%matplotlib inline
Connect to Neo4j¶
It is assumed that the Cora dataset has already been loaded into Neo4j. This notebook demonstrates how to load Cora dataset into Neo4j.
[4]:
import py2neo
default_host = os.environ.get("STELLARGRAPH_NEO4J_HOST")
# Create the Neo4j Graph database object; port, user, password parameters can be add to specify location and authentication
neo4j_graphdb = py2neo.Graph(host=default_host)
Create a Neo4jStellarGraph object¶
Using the py2neo.Graph instance, we can create a Neo4jStellarGraph object that will be useful for the rest of the stellargraph workflow.
For this demo, we introduce two additional details that help us execute the notebook faster:
Our Cora dataset loaded into Neo4j has an index on the
IDproperty ofpaperentities. By specifying thenode_labelparameter when constructingNeo4jStellarGraph, this lets downstream queries to use this index and therefore run much faster, since many of the queries will require matching nodes by theirID.We also cache the node features in memory. Since we know the graph is relatively small, we can safely cache the node features in memory for faster access. Note that this should be avoided for larger graphs where the node features are large.
[5]:
neo4j_sg = Neo4jStellarGraph(neo4j_graphdb, node_label="paper")
neo4j_sg.cache_all_nodes_in_memory()
Data labels¶
Each node has a “subject” property in the database, which we want to use as labels for training. We can load the labels into memory using a Cypher query and split them into training/test sets.
[6]:
labels_query = """
MATCH (node:paper)
WITH {ID: node.ID, label: node.subject} as node_data
RETURN node_data
"""
rows = neo4j_graphdb.run(labels_query).data()
labels = pd.Series(
[r["node_data"]["label"] for r in rows], index=[r["node_data"]["ID"] for r in rows]
)
[7]:
# split the node labels into train/test
train_labels, test_labels = model_selection.train_test_split(
labels, train_size=0.1, test_size=None, stratify=labels
)
target_encoding = preprocessing.LabelBinarizer()
train_targets = target_encoding.fit_transform(train_labels)
test_targets = target_encoding.transform(test_labels)
Creating the GraphSAGE model in Keras¶
To feed data from the graph to the Keras model we need a data generator that feeds data from the graph to the model. The generators are specialized to the model and the learning task so we choose the Neo4jGraphSAGENodeGenerator as we are predicting node attributes with a GraphSAGE model, sampling directly from Neo4j database.
We need two other parameters, the batch_size to use for training and the number of nodes to sample at each level of the model. Here we choose a two-level model with 10 nodes sampled in the first layer, and 5 in the second.
[8]:
batch_size = 50
num_samples = [10, 5]
epochs = 20
A Neo4jGraphSAGENodeGenerator object is required to send the node features in sampled subgraphs to Keras.
[9]:
generator = Neo4jGraphSAGENodeGenerator(neo4j_sg, batch_size, num_samples)
Using the generator.flow() method, we can create iterators over nodes that should be used to train, validate, or evaluate the model. For training we use only the training nodes returned from our splitter and the target values. The shuffle=True argument is given to the flow method to improve training.
[10]:
train_gen = generator.flow(train_labels.index, train_targets, shuffle=True)
Now we can specify our machine learning model, we need a few more parameters for this:
the
layer_sizesis a list of hidden feature sizes of each layer in the model. In this example we use 32-dimensional hidden node features at each layer.The
biasanddropoutare internal parameters of the model.
[11]:
graphsage_model = GraphSAGE(
layer_sizes=[32, 32], generator=generator, bias=True, dropout=0.5,
)
Now we create a model to predict the 7 categories using Keras softmax layers.
[12]:
x_inp, x_out = graphsage_model.in_out_tensors()
prediction = layers.Dense(units=train_targets.shape[1], activation="softmax")(x_out)
Training the model¶
Now let’s create the actual Keras model with the graph inputs x_inp provided by the graph_model and outputs being the predictions from the softmax layer
[13]:
model = Model(inputs=x_inp, outputs=prediction)
model.compile(
optimizer=optimizers.Adam(lr=0.005),
loss=losses.categorical_crossentropy,
metrics=["acc"],
)
Train the model, keeping track of its loss and accuracy on the training set, and its generalisation performance on the test set (we need to create another generator over the test data for this)
[14]:
test_gen = generator.flow(test_labels.index, test_targets)
[15]:
history = model.fit(
train_gen, epochs=epochs, validation_data=test_gen, verbose=2, shuffle=False
)
Epoch 1/20
6/6 - 6s - loss: 1.8420 - acc: 0.3000 - val_loss: 1.6646 - val_acc: 0.3888
Epoch 2/20
6/6 - 6s - loss: 1.5992 - acc: 0.4704 - val_loss: 1.4935 - val_acc: 0.5447
Epoch 3/20
6/6 - 6s - loss: 1.4202 - acc: 0.6741 - val_loss: 1.3581 - val_acc: 0.6653
Epoch 4/20
6/6 - 6s - loss: 1.2718 - acc: 0.7889 - val_loss: 1.2407 - val_acc: 0.7215
Epoch 5/20
6/6 - 5s - loss: 1.1286 - acc: 0.8593 - val_loss: 1.1424 - val_acc: 0.7543
Epoch 6/20
6/6 - 5s - loss: 1.0310 - acc: 0.8852 - val_loss: 1.0652 - val_acc: 0.7732
Epoch 7/20
6/6 - 5s - loss: 0.9338 - acc: 0.8926 - val_loss: 1.0227 - val_acc: 0.7580
Epoch 8/20
6/6 - 5s - loss: 0.8403 - acc: 0.9296 - val_loss: 0.9651 - val_acc: 0.7633
Epoch 9/20
6/6 - 5s - loss: 0.7482 - acc: 0.9481 - val_loss: 0.9277 - val_acc: 0.7908
Epoch 10/20
6/6 - 6s - loss: 0.6885 - acc: 0.9778 - val_loss: 0.8926 - val_acc: 0.7945
Epoch 11/20
6/6 - 6s - loss: 0.6433 - acc: 0.9667 - val_loss: 0.8423 - val_acc: 0.8068
Epoch 12/20
6/6 - 5s - loss: 0.5693 - acc: 0.9593 - val_loss: 0.8221 - val_acc: 0.8015
Epoch 13/20
6/6 - 5s - loss: 0.5259 - acc: 0.9778 - val_loss: 0.8009 - val_acc: 0.7986
Epoch 14/20
6/6 - 5s - loss: 0.4732 - acc: 0.9926 - val_loss: 0.7852 - val_acc: 0.7974
Epoch 15/20
6/6 - 5s - loss: 0.4317 - acc: 0.9889 - val_loss: 0.7527 - val_acc: 0.8093
Epoch 16/20
6/6 - 5s - loss: 0.4011 - acc: 0.9926 - val_loss: 0.7533 - val_acc: 0.8019
Epoch 17/20
6/6 - 5s - loss: 0.3802 - acc: 0.9889 - val_loss: 0.7341 - val_acc: 0.7986
Epoch 18/20
6/6 - 5s - loss: 0.3410 - acc: 0.9963 - val_loss: 0.7174 - val_acc: 0.8002
Epoch 19/20
6/6 - 5s - loss: 0.3153 - acc: 0.9815 - val_loss: 0.7141 - val_acc: 0.8023
Epoch 20/20
6/6 - 5s - loss: 0.2734 - acc: 1.0000 - val_loss: 0.7045 - val_acc: 0.8121
[16]:
sg.utils.plot_history(history)
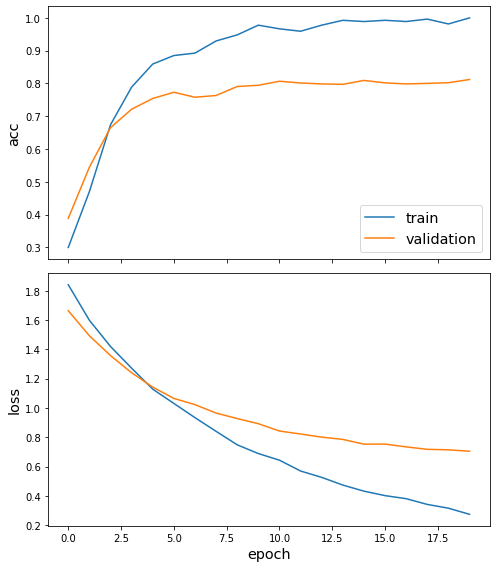
Now we have trained the model we can evaluate on the test set.
[17]:
test_metrics = model.evaluate(test_gen)
print("\nTest Set Metrics:")
for name, val in zip(model.metrics_names, test_metrics):
print("\t{}: {:0.4f}".format(name, val))
49/49 [==============================] - 5s 92ms/step - loss: 0.7004 - acc: 0.8105
Test Set Metrics:
loss: 0.7004
acc: 0.8105
Making predictions with the model¶
Now let’s get the predictions themselves for all nodes using another node iterator:
[18]:
all_nodes = labels.index
all_mapper = generator.flow(all_nodes)
all_predictions = model.predict(all_mapper)
These predictions will be the output of the softmax layer, so to get final categories we’ll use the inverse_transform method of our target attribute specification to turn these values back to the original categories
[19]:
node_predictions = target_encoding.inverse_transform(all_predictions)
Let’s have a look at a few:
[20]:
df = pd.DataFrame({"Predicted": node_predictions, "True": labels})
df.head(10)
[20]:
| Predicted | True | |
|---|---|---|
| 31336 | Neural_Networks | Neural_Networks |
| 1061127 | Rule_Learning | Rule_Learning |
| 1106406 | Reinforcement_Learning | Reinforcement_Learning |
| 13195 | Reinforcement_Learning | Reinforcement_Learning |
| 37879 | Probabilistic_Methods | Probabilistic_Methods |
| 1126012 | Probabilistic_Methods | Probabilistic_Methods |
| 1107140 | Reinforcement_Learning | Theory |
| 1102850 | Neural_Networks | Neural_Networks |
| 31349 | Neural_Networks | Neural_Networks |
| 1106418 | Theory | Theory |
Please refer to the non-Neo4j GraphSAGE node classification demo for node embedding visualization.
Execute this notebook:
![]()
![]() Download locally
Download locally
