Execute this notebook:
![]()
![]() Download locally
Download locally
Node classification with Graph Convolutional Network (GCN)¶
This demo explains how to do node classification using the StellarGraph library. See all other demos.
The StellarGraph library supports many state-of-the-art machine learning (ML) algorithms on graphs. In this notebook, we’ll be training a model to predict the class or label of a node, commonly known as node classification. We will also use the resulting model to compute vector embeddings for each node.
There’s two necessary parts to be able to do this task:
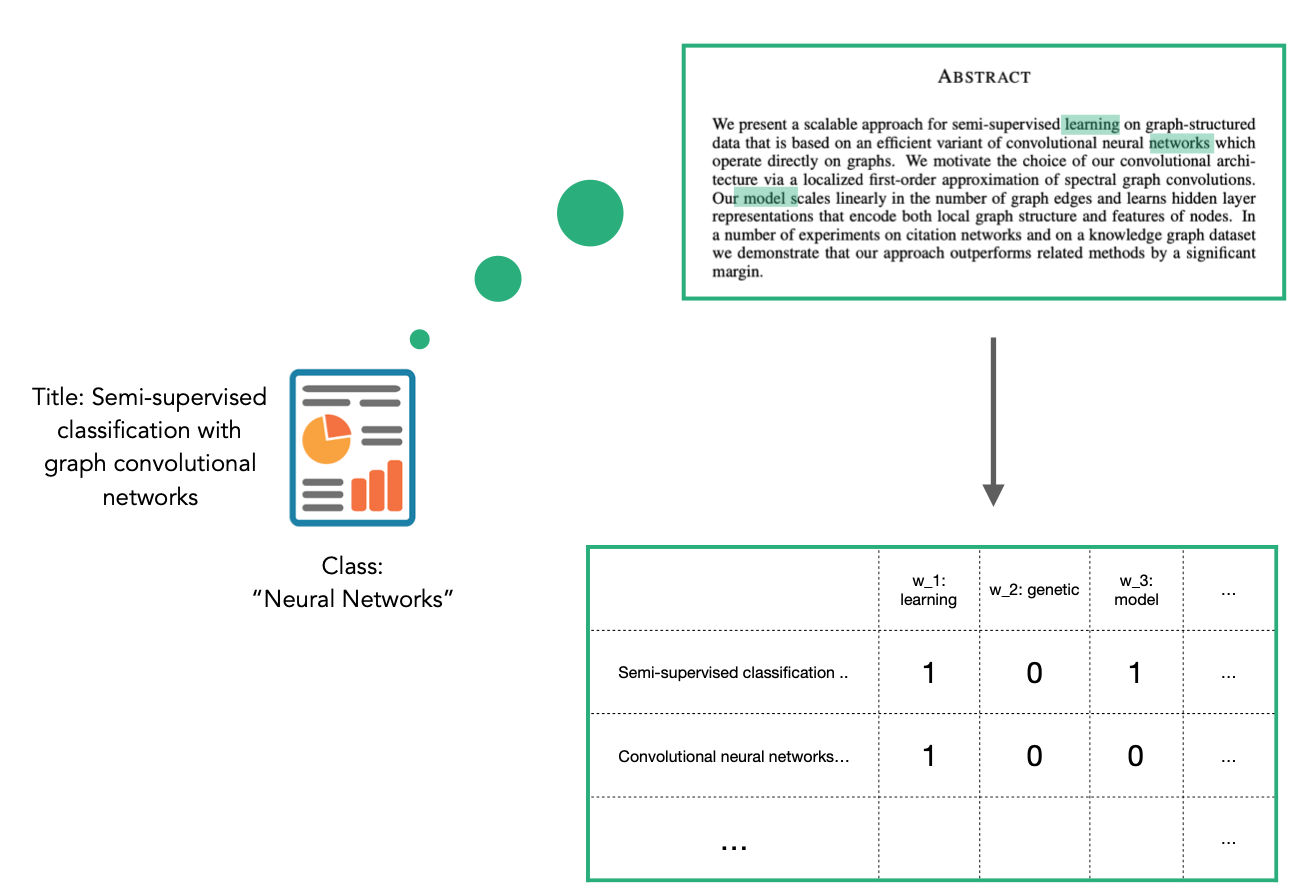
a graph: this notebook uses the Cora dataset from https://linqs.soe.ucsc.edu/data. The dataset consists of academic publications as the nodes and the citations between them as the links: if publication A cites publication B, then the graph has an edge from A to B. The nodes are classified into one of seven subjects, and our model will learn to predict this subject.
an algorithm: this notebook uses a Graph Convolution Network (GCN) [1]. The core of the GCN neural network model is a “graph convolution” layer. This layer is similar to a conventional dense layer, augmented by the graph adjacency matrix to use information about a node’s connections. This algorithm is discussed in more detail in “Knowing Your Neighbours: Machine Learning on Graphs”.
The notebook walks through three sections:
Data preparation using Pandas and scikit-learn: loading the graph from CSV files, doing some basic introspection, and splitting it into train, test and validation splits for ML
Creating the GCN layers and data input using StellarGraph
Training and evaluating the model using TensorFlow Keras, Pandas and scikit-learn
Notably, only section 2 needs StellarGraph: section 1 and section 3 are driven by the existing flexible functionality in common and popular data science libraries. Most of the algorithms supported by StellarGraph follow this pattern, where the custom StellarGraph functionality integrates smoothly with the conventional data science work-flow.
StellarGraph supports other algorithms for doing node classification, as well as many other tasks such as link prediction, and representation learning.
[1]: Graph Convolutional Networks (GCN): Semi-Supervised Classification with Graph Convolutional Networks. Thomas N. Kipf, Max Welling. International Conference on Learning Representations (ICLR), 2017
The first step is to import the Python libraries that we’ll need. We import stellargraph under the sg name for convenience, similar to pandas often being imported as pd.
[3]:
import pandas as pd
import os
import stellargraph as sg
from stellargraph.mapper import FullBatchNodeGenerator
from stellargraph.layer import GCN
from tensorflow.keras import layers, optimizers, losses, metrics, Model
from sklearn import preprocessing, model_selection
from IPython.display import display, HTML
import matplotlib.pyplot as plt
%matplotlib inline
1. Data Preparation¶
Loading the CORA network¶
We can retrieve a StellarGraph graph object holding this Cora dataset using the Cora loader (docs) from the datasets submodule (docs). It also provides us with the ground-truth node subject classes. This function is implemented using Pandas, see the “Loading data into StellarGraph from Pandas”
notebook for details.
(Note: Cora is a citation network, which is a directed graph, but, like most users of this graph, we ignore the edge direction and treat it as undirected.)
(See the “Loading from Pandas” demo for details on how data can be loaded.)
[4]:
dataset = sg.datasets.Cora()
display(HTML(dataset.description))
G, node_subjects = dataset.load()
The info method can help us verify that our loaded graph matches the description:
[5]:
print(G.info())
StellarGraph: Undirected multigraph
Nodes: 2708, Edges: 5429
Node types:
paper: [2708]
Features: float32 vector, length 1433
Edge types: paper-cites->paper
Edge types:
paper-cites->paper: [5429]
We aim to train a graph-ML model that will predict the “subject” attribute on the nodes. These subjects are one of 7 categories, with some categories more common than others:
[6]:
node_subjects.value_counts().to_frame()
[6]:
| subject | |
|---|---|
| Neural_Networks | 818 |
| Probabilistic_Methods | 426 |
| Genetic_Algorithms | 418 |
| Theory | 351 |
| Case_Based | 298 |
| Reinforcement_Learning | 217 |
| Rule_Learning | 180 |
Splitting the data¶
For machine learning we want to take a subset of the nodes for training, and use the rest for validation and testing. We’ll use scikit-learn’s train_test_split function (docs) to do this.
Here we’re taking 140 node labels for training, 500 for validation, and the rest for testing.
[7]:
train_subjects, test_subjects = model_selection.train_test_split(
node_subjects, train_size=140, test_size=None, stratify=node_subjects
)
val_subjects, test_subjects = model_selection.train_test_split(
test_subjects, train_size=500, test_size=None, stratify=test_subjects
)
Note using stratified sampling gives the following counts:
[8]:
train_subjects.value_counts().to_frame()
[8]:
| subject | |
|---|---|
| Neural_Networks | 42 |
| Genetic_Algorithms | 22 |
| Probabilistic_Methods | 22 |
| Theory | 18 |
| Case_Based | 16 |
| Reinforcement_Learning | 11 |
| Rule_Learning | 9 |
The training set has class imbalance that might need to be compensated, e.g., via using a weighted cross-entropy loss in model training, with class weights inversely proportional to class support. However, we will ignore the class imbalance in this example, for simplicity.
Converting to numeric arrays¶
For our categorical target, we will use one-hot vectors that will be compared against the model’s soft-max output. To do this conversion we can use the LabelBinarizer transform (docs) from scikit-learn. Another option would be the pandas.get_dummies function (docs), but the scikit-learn transform allows
us to do the inverse transform easily later in the notebook, to interpret the predictions.
[9]:
target_encoding = preprocessing.LabelBinarizer()
train_targets = target_encoding.fit_transform(train_subjects)
val_targets = target_encoding.transform(val_subjects)
test_targets = target_encoding.transform(test_subjects)
The CORA dataset contains attributes w_x that correspond to words found in that publication. If a word occurs more than once in a publication the relevant attribute will be set to one, otherwise it will be zero. These numeric attributes have been automatically included in the StellarGraph instance G, and so we do not have to do any further conversion.
2. Creating the GCN layers¶
A machine learning model in StellarGraph consists of a pair of items:
the layers themselves, such as graph convolution, dropout and even conventional dense layers
a data generator to convert the core graph structure and node features into a format that can be fed into the Keras model for training or prediction
GCN is a full-batch model and we’re doing node classification here, which means the FullBatchNodeGenerator class (docs) is the appropriate generator for our task. StellarGraph has many generators in order to support all its many models and tasks.
Specifying the method='gcn' argument to the FullBatchNodeGenerator means it will yield data appropriate for the GCN algorithm specifically, by using the normalized graph Laplacian matrix to capture the graph structure.
[10]:
generator = FullBatchNodeGenerator(G, method="gcn")
Using GCN (local pooling) filters...
A generator just encodes the information required to produce the model inputs. Calling the flow method (docs) with a set of nodes and their true labels produces an object that can be used to train the model, on those nodes and labels that were specified. We created a training set above, so that’s what we’re going to use here.
[11]:
train_gen = generator.flow(train_subjects.index, train_targets)
Now we can specify our machine learning model by building a stack of layers. We can use StellarGraph’s GCN class (docs), which packages up the creation of this stack of graph convolution and dropout layers. We can specify a few parameters to
control this:
layer_sizes: the number of hidden GCN layers and their sizes. In this case, two GCN layers with 16 units each.activations: the activation to apply to each GCN layer’s output. In this case, RelU for both layers.dropout: the rate of dropout for the input of each GCN layer. In this case, 50%.
[12]:
gcn = GCN(
layer_sizes=[16, 16], activations=["relu", "relu"], generator=generator, dropout=0.5
)
To create a Keras model we now expose the input and output tensors of the GCN model for node prediction, via the GCN.in_out_tensors method:
[13]:
x_inp, x_out = gcn.in_out_tensors()
x_out
[13]:
<tf.Tensor 'gather_indices/Identity:0' shape=(1, None, 16) dtype=float32>
The x_out value is a TensorFlow tensor that holds a 16-dimensional vector for the nodes requested when training or predicting. The actual predictions of each node’s class/subject needs to be computed from this vector. StellarGraph is built using Keras functionality, so this can be done with a standard Keras functionality: an additional dense layer (with one unit per class) using a softmax activation. This activation function ensures that the final outputs for each input node will be a vector
of “probabilities”, where every value is between 0 and 1, and the whole vector sums to 1. The predicted class is the element with the highest value.
[14]:
predictions = layers.Dense(units=train_targets.shape[1], activation="softmax")(x_out)
3. Training and evaluating¶
Training the model¶
Now let’s create the actual Keras model with the input tensors x_inp and output tensors being the predictions predictions from the final dense layer. Our task is a categorical prediction task, so a categorical cross-entropy loss function is appropriate. Even though we’re doing graph ML with StellarGraph, we’re still working with conventional Keras prediction values, so we can use the loss function from
Keras directly.
[15]:
model = Model(inputs=x_inp, outputs=predictions)
model.compile(
optimizer=optimizers.Adam(lr=0.01),
loss=losses.categorical_crossentropy,
metrics=["acc"],
)
As we’re training the model, we’ll want to also keep track of its generalisation performance on the validation set, which means creating another data generator, using our FullBatchNodeGenerator we created above.
[16]:
val_gen = generator.flow(val_subjects.index, val_targets)
We can directly use the EarlyStopping functionality (docs) offered by Keras to stop training if the validation accuracy stops improving.
[17]:
from tensorflow.keras.callbacks import EarlyStopping
es_callback = EarlyStopping(monitor="val_acc", patience=50, restore_best_weights=True)
We’ve now set up our model layers, our training data, our validation data and even our training callbacks, so we can now train the model using the model’s fit method (docs). Like most things in this section, this is all built into Keras.
[18]:
history = model.fit(
train_gen,
epochs=200,
validation_data=val_gen,
verbose=2,
shuffle=False, # this should be False, since shuffling data means shuffling the whole graph
callbacks=[es_callback],
)
['...']
['...']
Train for 1 steps, validate for 1 steps
Epoch 1/200
1/1 - 1s - loss: 1.9505 - acc: 0.1000 - val_loss: 1.9182 - val_acc: 0.2820
Epoch 2/200
1/1 - 0s - loss: 1.9004 - acc: 0.3143 - val_loss: 1.8831 - val_acc: 0.3560
Epoch 3/200
1/1 - 0s - loss: 1.8493 - acc: 0.3571 - val_loss: 1.8297 - val_acc: 0.3940
Epoch 4/200
1/1 - 0s - loss: 1.7679 - acc: 0.4500 - val_loss: 1.7643 - val_acc: 0.3700
Epoch 5/200
1/1 - 0s - loss: 1.6747 - acc: 0.4500 - val_loss: 1.7046 - val_acc: 0.3580
Epoch 6/200
1/1 - 0s - loss: 1.5794 - acc: 0.4643 - val_loss: 1.6489 - val_acc: 0.3780
Epoch 7/200
1/1 - 0s - loss: 1.5086 - acc: 0.4714 - val_loss: 1.5843 - val_acc: 0.4440
Epoch 8/200
1/1 - 0s - loss: 1.4128 - acc: 0.5071 - val_loss: 1.5189 - val_acc: 0.5180
Epoch 9/200
1/1 - 0s - loss: 1.2905 - acc: 0.5929 - val_loss: 1.4558 - val_acc: 0.5900
Epoch 10/200
1/1 - 0s - loss: 1.1587 - acc: 0.6714 - val_loss: 1.3988 - val_acc: 0.6320
Epoch 11/200
1/1 - 0s - loss: 1.1166 - acc: 0.7143 - val_loss: 1.3416 - val_acc: 0.6620
Epoch 12/200
1/1 - 0s - loss: 1.0452 - acc: 0.7500 - val_loss: 1.2856 - val_acc: 0.6740
Epoch 13/200
1/1 - 0s - loss: 1.0205 - acc: 0.7286 - val_loss: 1.2315 - val_acc: 0.6880
Epoch 14/200
1/1 - 0s - loss: 0.8734 - acc: 0.7786 - val_loss: 1.1815 - val_acc: 0.6880
Epoch 15/200
1/1 - 0s - loss: 0.7818 - acc: 0.7857 - val_loss: 1.1342 - val_acc: 0.6940
Epoch 16/200
1/1 - 0s - loss: 0.7580 - acc: 0.8143 - val_loss: 1.0892 - val_acc: 0.7020
Epoch 17/200
1/1 - 0s - loss: 0.6956 - acc: 0.8143 - val_loss: 1.0459 - val_acc: 0.7120
Epoch 18/200
1/1 - 0s - loss: 0.5902 - acc: 0.8214 - val_loss: 1.0059 - val_acc: 0.7180
Epoch 19/200
1/1 - 0s - loss: 0.5497 - acc: 0.8786 - val_loss: 0.9683 - val_acc: 0.7420
Epoch 20/200
1/1 - 0s - loss: 0.4658 - acc: 0.8929 - val_loss: 0.9342 - val_acc: 0.7520
Epoch 21/200
1/1 - 0s - loss: 0.4416 - acc: 0.8857 - val_loss: 0.9039 - val_acc: 0.7760
Epoch 22/200
1/1 - 0s - loss: 0.4374 - acc: 0.9071 - val_loss: 0.8786 - val_acc: 0.7860
Epoch 23/200
1/1 - 0s - loss: 0.3275 - acc: 0.9500 - val_loss: 0.8585 - val_acc: 0.7860
Epoch 24/200
1/1 - 0s - loss: 0.3131 - acc: 0.9429 - val_loss: 0.8451 - val_acc: 0.7920
Epoch 25/200
1/1 - 0s - loss: 0.3186 - acc: 0.9357 - val_loss: 0.8369 - val_acc: 0.8000
Epoch 26/200
1/1 - 0s - loss: 0.2150 - acc: 0.9786 - val_loss: 0.8352 - val_acc: 0.7940
Epoch 27/200
1/1 - 0s - loss: 0.2385 - acc: 0.9643 - val_loss: 0.8335 - val_acc: 0.7940
Epoch 28/200
1/1 - 0s - loss: 0.2191 - acc: 0.9500 - val_loss: 0.8330 - val_acc: 0.7940
Epoch 29/200
1/1 - 0s - loss: 0.1988 - acc: 0.9643 - val_loss: 0.8297 - val_acc: 0.7940
Epoch 30/200
1/1 - 0s - loss: 0.1957 - acc: 0.9500 - val_loss: 0.8282 - val_acc: 0.8040
Epoch 31/200
1/1 - 0s - loss: 0.1622 - acc: 0.9500 - val_loss: 0.8281 - val_acc: 0.8020
Epoch 32/200
1/1 - 0s - loss: 0.1748 - acc: 0.9571 - val_loss: 0.8307 - val_acc: 0.8100
Epoch 33/200
1/1 - 0s - loss: 0.1223 - acc: 0.9714 - val_loss: 0.8360 - val_acc: 0.8120
Epoch 34/200
1/1 - 0s - loss: 0.1208 - acc: 0.9857 - val_loss: 0.8433 - val_acc: 0.8160
Epoch 35/200
1/1 - 0s - loss: 0.1331 - acc: 0.9714 - val_loss: 0.8526 - val_acc: 0.8120
Epoch 36/200
1/1 - 0s - loss: 0.1015 - acc: 0.9714 - val_loss: 0.8610 - val_acc: 0.8140
Epoch 37/200
1/1 - 0s - loss: 0.1253 - acc: 0.9714 - val_loss: 0.8680 - val_acc: 0.8180
Epoch 38/200
1/1 - 0s - loss: 0.0815 - acc: 0.9857 - val_loss: 0.8766 - val_acc: 0.8240
Epoch 39/200
1/1 - 0s - loss: 0.0822 - acc: 0.9857 - val_loss: 0.8847 - val_acc: 0.8200
Epoch 40/200
1/1 - 0s - loss: 0.0677 - acc: 0.9857 - val_loss: 0.8942 - val_acc: 0.8160
Epoch 41/200
1/1 - 0s - loss: 0.0633 - acc: 0.9786 - val_loss: 0.9061 - val_acc: 0.8140
Epoch 42/200
1/1 - 0s - loss: 0.0767 - acc: 0.9857 - val_loss: 0.9204 - val_acc: 0.8140
Epoch 43/200
1/1 - 0s - loss: 0.0427 - acc: 0.9929 - val_loss: 0.9353 - val_acc: 0.8120
Epoch 44/200
1/1 - 0s - loss: 0.1346 - acc: 0.9429 - val_loss: 0.9500 - val_acc: 0.8080
Epoch 45/200
1/1 - 0s - loss: 0.0318 - acc: 1.0000 - val_loss: 0.9651 - val_acc: 0.8100
Epoch 46/200
1/1 - 0s - loss: 0.0409 - acc: 0.9929 - val_loss: 0.9797 - val_acc: 0.8020
Epoch 47/200
1/1 - 0s - loss: 0.0551 - acc: 0.9786 - val_loss: 0.9891 - val_acc: 0.8040
Epoch 48/200
1/1 - 0s - loss: 0.0645 - acc: 0.9714 - val_loss: 0.9956 - val_acc: 0.8040
Epoch 49/200
1/1 - 0s - loss: 0.0550 - acc: 0.9857 - val_loss: 0.9981 - val_acc: 0.8020
Epoch 50/200
1/1 - 0s - loss: 0.0223 - acc: 1.0000 - val_loss: 0.9984 - val_acc: 0.8020
Epoch 51/200
1/1 - 0s - loss: 0.0533 - acc: 0.9857 - val_loss: 0.9987 - val_acc: 0.8040
Epoch 52/200
1/1 - 0s - loss: 0.0389 - acc: 1.0000 - val_loss: 0.9986 - val_acc: 0.8060
Epoch 53/200
1/1 - 0s - loss: 0.0559 - acc: 0.9929 - val_loss: 0.9956 - val_acc: 0.8060
Epoch 54/200
1/1 - 0s - loss: 0.0316 - acc: 0.9929 - val_loss: 0.9950 - val_acc: 0.8080
Epoch 55/200
1/1 - 0s - loss: 0.0392 - acc: 0.9857 - val_loss: 0.9925 - val_acc: 0.8060
Epoch 56/200
1/1 - 0s - loss: 0.0476 - acc: 0.9857 - val_loss: 0.9934 - val_acc: 0.8060
Epoch 57/200
1/1 - 0s - loss: 0.0574 - acc: 0.9857 - val_loss: 0.9916 - val_acc: 0.8080
Epoch 58/200
1/1 - 0s - loss: 0.0727 - acc: 0.9714 - val_loss: 0.9905 - val_acc: 0.8120
Epoch 59/200
1/1 - 0s - loss: 0.0540 - acc: 0.9857 - val_loss: 0.9890 - val_acc: 0.8080
Epoch 60/200
1/1 - 0s - loss: 0.0544 - acc: 0.9786 - val_loss: 0.9886 - val_acc: 0.8100
Epoch 61/200
1/1 - 0s - loss: 0.0553 - acc: 0.9929 - val_loss: 0.9901 - val_acc: 0.8100
Epoch 62/200
1/1 - 0s - loss: 0.0402 - acc: 0.9929 - val_loss: 0.9908 - val_acc: 0.8080
Epoch 63/200
1/1 - 0s - loss: 0.0172 - acc: 1.0000 - val_loss: 0.9922 - val_acc: 0.8100
Epoch 64/200
1/1 - 0s - loss: 0.0376 - acc: 0.9929 - val_loss: 0.9929 - val_acc: 0.8080
Epoch 65/200
1/1 - 0s - loss: 0.0247 - acc: 0.9929 - val_loss: 0.9941 - val_acc: 0.8100
Epoch 66/200
1/1 - 0s - loss: 0.1193 - acc: 0.9571 - val_loss: 0.9894 - val_acc: 0.8100
Epoch 67/200
1/1 - 0s - loss: 0.0259 - acc: 0.9929 - val_loss: 0.9872 - val_acc: 0.8080
Epoch 68/200
1/1 - 0s - loss: 0.0136 - acc: 1.0000 - val_loss: 0.9872 - val_acc: 0.8140
Epoch 69/200
1/1 - 0s - loss: 0.0250 - acc: 1.0000 - val_loss: 0.9908 - val_acc: 0.8160
Epoch 70/200
1/1 - 0s - loss: 0.0392 - acc: 0.9929 - val_loss: 0.9970 - val_acc: 0.8220
Epoch 71/200
1/1 - 0s - loss: 0.0253 - acc: 1.0000 - val_loss: 1.0030 - val_acc: 0.8140
Epoch 72/200
1/1 - 0s - loss: 0.0219 - acc: 1.0000 - val_loss: 1.0105 - val_acc: 0.8140
Epoch 73/200
1/1 - 0s - loss: 0.0206 - acc: 0.9929 - val_loss: 1.0190 - val_acc: 0.8080
Epoch 74/200
1/1 - 0s - loss: 0.0228 - acc: 1.0000 - val_loss: 1.0272 - val_acc: 0.8060
Epoch 75/200
1/1 - 0s - loss: 0.0211 - acc: 0.9929 - val_loss: 1.0353 - val_acc: 0.8040
Epoch 76/200
1/1 - 0s - loss: 0.0355 - acc: 0.9857 - val_loss: 1.0439 - val_acc: 0.8020
Epoch 77/200
1/1 - 0s - loss: 0.0325 - acc: 0.9857 - val_loss: 1.0548 - val_acc: 0.7980
Epoch 78/200
1/1 - 0s - loss: 0.0235 - acc: 1.0000 - val_loss: 1.0655 - val_acc: 0.8000
Epoch 79/200
1/1 - 0s - loss: 0.0266 - acc: 0.9929 - val_loss: 1.0742 - val_acc: 0.8000
Epoch 80/200
1/1 - 0s - loss: 0.0585 - acc: 0.9857 - val_loss: 1.0839 - val_acc: 0.8040
Epoch 81/200
1/1 - 0s - loss: 0.0626 - acc: 0.9857 - val_loss: 1.0925 - val_acc: 0.7980
Epoch 82/200
1/1 - 0s - loss: 0.0198 - acc: 1.0000 - val_loss: 1.1006 - val_acc: 0.7980
Epoch 83/200
1/1 - 0s - loss: 0.0259 - acc: 0.9929 - val_loss: 1.1047 - val_acc: 0.8000
Epoch 84/200
1/1 - 0s - loss: 0.0296 - acc: 0.9929 - val_loss: 1.1079 - val_acc: 0.8020
Epoch 85/200
1/1 - 0s - loss: 0.0236 - acc: 0.9929 - val_loss: 1.1077 - val_acc: 0.8060
Epoch 86/200
1/1 - 0s - loss: 0.0440 - acc: 0.9714 - val_loss: 1.1033 - val_acc: 0.8040
Epoch 87/200
1/1 - 0s - loss: 0.0324 - acc: 0.9929 - val_loss: 1.0994 - val_acc: 0.8020
Epoch 88/200
1/1 - 0s - loss: 0.0359 - acc: 0.9857 - val_loss: 1.0955 - val_acc: 0.8040
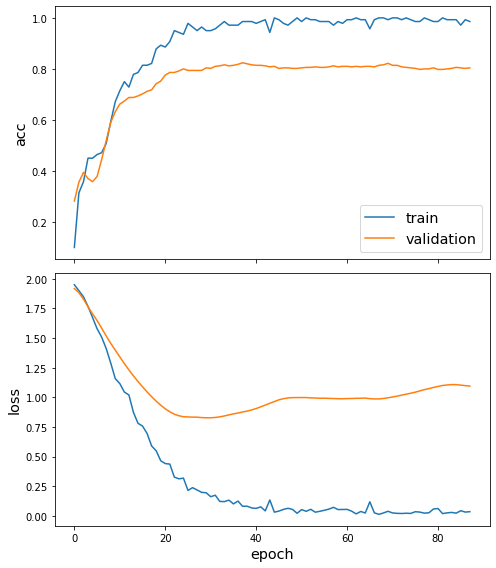
Once we’ve trained the model, we can view the behaviour loss function and any other metrics using the plot_history function (docs). In this case, we can see the loss and accuracy on both the training and validation sets.
[19]:
sg.utils.plot_history(history)
As the final part of our evaluation, let’s check the model against the test set. We again create the data required for this using the flow method on our FullBatchNodeGenerator from above, and can use the model’s evaluate method (docs) to compute the metric values for the trained model.
As expected, the model performs similarly on the validation set during training and on the test set here.
[20]:
test_gen = generator.flow(test_subjects.index, test_targets)
[21]:
test_metrics = model.evaluate(test_gen)
print("\nTest Set Metrics:")
for name, val in zip(model.metrics_names, test_metrics):
print("\t{}: {:0.4f}".format(name, val))
['...']
1/1 [==============================] - 0s 11ms/step - loss: 0.6904 - acc: 0.8298
Test Set Metrics:
loss: 0.6904
acc: 0.8298
Making predictions with the model¶
Now let’s get the predictions for all nodes. You’re probably getting used to it by now, but we use our FullBatchNodeGenerator to create the input required and then use one of the model’s methods: predict (docs). This time we don’t provide the labels to flow, and instead just the nodes, because we’re trying to predict these classes without knowing them.
[22]:
all_nodes = node_subjects.index
all_gen = generator.flow(all_nodes)
all_predictions = model.predict(all_gen)
These predictions will be the output of the softmax layer, so to get final categories we’ll use the inverse_transform method of our target attribute specification to turn these values back to the original categories.
Note that for full-batch methods the batch size is 1 and the predictions have shape \((1, N_{nodes}, N_{classes})\) so we we remove the batch dimension to obtain predictions of shape \((N_{nodes}, N_{classes})\) using the NumPy squeeze method.
[23]:
node_predictions = target_encoding.inverse_transform(all_predictions.squeeze())
Let’s have a look at a few predictions after training the model:
[24]:
df = pd.DataFrame({"Predicted": node_predictions, "True": node_subjects})
df.head(20)
[24]:
| Predicted | True | |
|---|---|---|
| 31336 | Neural_Networks | Neural_Networks |
| 1061127 | Rule_Learning | Rule_Learning |
| 1106406 | Reinforcement_Learning | Reinforcement_Learning |
| 13195 | Reinforcement_Learning | Reinforcement_Learning |
| 37879 | Probabilistic_Methods | Probabilistic_Methods |
| 1126012 | Probabilistic_Methods | Probabilistic_Methods |
| 1107140 | Reinforcement_Learning | Theory |
| 1102850 | Neural_Networks | Neural_Networks |
| 31349 | Neural_Networks | Neural_Networks |
| 1106418 | Theory | Theory |
| 1123188 | Probabilistic_Methods | Neural_Networks |
| 1128990 | Reinforcement_Learning | Genetic_Algorithms |
| 109323 | Probabilistic_Methods | Probabilistic_Methods |
| 217139 | Case_Based | Case_Based |
| 31353 | Neural_Networks | Neural_Networks |
| 32083 | Neural_Networks | Neural_Networks |
| 1126029 | Reinforcement_Learning | Reinforcement_Learning |
| 1118017 | Neural_Networks | Neural_Networks |
| 49482 | Neural_Networks | Neural_Networks |
| 753265 | Theory | Neural_Networks |
Node embeddings¶
In addition to just predicting the node class, it can be useful to get a more detailed picture of what information the model has learnt about the nodes and their neighbourhoods. In this case, this means an embedding of the node (also called a “representation”) into a latent vector space that captures that information, and it comes in the form of either a look-up table mapping node to a vector of numbers, or a neural network that produces those vectors. For GCN, we’re going to be using the second
option, using the last graph convolution layer of the GCN model (called x_out above), before we applied the prediction layer.
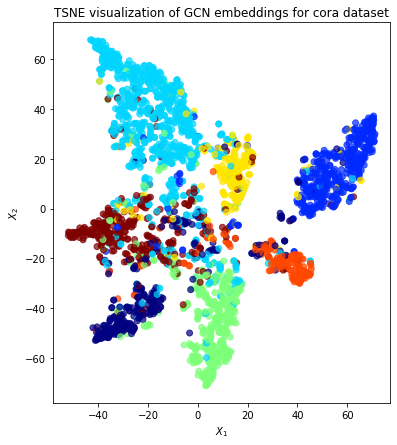
We can visualise these embeddings as points on a plot, colored by their true subject labels. If the model has learned useful information about the nodes based on their class, we expect to see nice clusters of papers in the node embedding space, with papers of the same subject belonging to the same cluster.
To create a model that computes node embeddings, we use the same input tensors (x_inp) as the prediction model above, and just swap the output tensor to the GCN one (x_out) instead of the prediction layer. These tensors are connected to the same layers and weights that we trained when training the predictions above, and so we’re only using this model to compute/”predict” the node embedding vectors. Similar to doing predictions for every node, we will compute embeddings for every node
using the all_gen data.
[25]:
embedding_model = Model(inputs=x_inp, outputs=x_out)
[26]:
emb = embedding_model.predict(all_gen)
emb.shape
[26]:
(1, 2708, 16)
The last GCN layer had output dimension 16, meaning each embedding consists of 16 numbers. Plotting this directly would require a 16 dimensional plot, which is hard for humans to visualise. Instead, we can first project these vectors down to just 2 numbers, making vectors of dimension 2 that can be plotted on a normal 2D scatter plot.
There are many tools for this dimensionality reduction task, many of which are offered by scikit-learn. Two of the more common ones are principal component analysis (PCA) (which is linear) and t-distributed Stochastic Neighbor Embedding (t-SNE or TSNE) (non-linear). t-SNE is slower but typically gives nicer results for plotting.
[27]:
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
transform = TSNE # or PCA
Note that the embeddings from the GCN model have a batch dimension of 1 so we squeeze this to get a matrix of \(N_{nodes} \times N_{emb}\).
[28]:
X = emb.squeeze(0)
X.shape
[28]:
(2708, 16)
We’ve thus prepared our high-dimension embeddings and chosen our dimension-reduction transform, so we now compute the reduced vectors, as two columns of the new values.
[29]:
trans = transform(n_components=2)
X_reduced = trans.fit_transform(X)
X_reduced.shape
[29]:
(2708, 2)
The X_reduced values contains a pair of numbers for each node, in the same order as the node_subjects Series of ground-truth labels (because that’s how all_gen was created). This is enough to do a scatter plot of the nodes, with colors. We can let matplotlib compute the colors by mapping the subjects to integers 0, 1, …, 6, using Pandas’s support for categorical data.
Qualitatively, the plot shows good clustering, where nodes of a single colour are mostly grouped together.
[30]:
fig, ax = plt.subplots(figsize=(7, 7))
ax.scatter(
X_reduced[:, 0],
X_reduced[:, 1],
c=node_subjects.astype("category").cat.codes,
cmap="jet",
alpha=0.7,
)
ax.set(
aspect="equal",
xlabel="$X_1$",
ylabel="$X_2$",
title=f"{transform.__name__} visualization of GCN embeddings for cora dataset",
)
[30]:
[Text(0, 0.5, '$X_2$'),
Text(0.5, 0, '$X_1$'),
Text(0.5, 1.0, 'TSNE visualization of GCN embeddings for cora dataset'),
None]
Conclusion¶
This notebook gave an example using the GCN algorithm to predict the class of nodes. Specifically, the subject of an academic paper in the Cora dataset. Our model used:
the graph structure of the dataset, in the form of citation links between papers
the 1433-dimensional feature vectors associated with each paper
Once we trained a model for prediction, we could:
predict the classes of nodes
use the model’s weights to compute vector embeddings for nodes
This notebook ran through the following steps:
prepared the data using common data science libraries
built a TensorFlow Keras model and data generator with the StellarGraph library
trained and evaluated it using TensorFlow and other libraries
For problems with only small amounts of labelled data, model performance can be improved by semi-supervised training. See the GCN + Deep Graph Infomax fine-tuning demo for more details on how to do this.
StellarGraph includes other algorithms for node classification and algorithms and demos for other tasks. Most can be applied with the same basic structure as this GCN demo.
Execute this notebook:
![]()
![]() Download locally
Download locally
