Execute this notebook:
![]()
![]() Download locally
Download locally
Ensemble models for link prediction¶
In this example, we use stellargraphs BaggingEnsemble class of GraphSAGE models to predict citation links in the Cora dataset (see below). The BaggingEnsemble class brings ensemble learning to stellargraph’s graph neural network models, e.g., GraphSAGE, quantifying prediction variance and potentially improving prediction accuracy.
The problem is treated as a supervised link prediction problem on a homogeneous citation network with nodes representing papers (with attributes such as binary keyword indicators and categorical subject) and links corresponding to paper-paper citations.
To address this problem, we build a a base GraphSAGE model with the following architecture. First we build a two-layer GraphSAGE model that takes labeled (paper1, paper2) node pairs corresponding to possible citation links, and outputs a pair of node embeddings for the paper1 and paper2 nodes of the pair. These embeddings are then fed into a link classification layer, which first applies a binary operator to those node embeddings (e.g., concatenating them) to construct the
embedding of the potential link. Thus obtained link embeddings are passed through the dense link classification layer to obtain link predictions - probability for these candidate links to actually exist in the network. The entire model is trained end-to-end by minimizing the loss function of choice (e.g., binary cross-entropy between predicted link probabilities and true link labels, with true/false citation links having labels 1/0) using stochastic gradient descent (SGD) updates of the model
parameters, with minibatches of ‘training’ links fed into the model.
Finally, using our base model, we create an ensemble with each model in the ensemble trained on a bootstrapped sample of the training data.
References
Inductive Representation Learning on Large Graphs. W.L. Hamilton, R. Ying, and J. Leskovec arXiv:1706.02216 [cs.SI], 2017.
[3]:
import matplotlib.pyplot as plt
import networkx as nx
import pandas as pd
import numpy as np
from tensorflow import keras
import os
import stellargraph as sg
from stellargraph.data import EdgeSplitter
from stellargraph.mapper import GraphSAGELinkGenerator
from stellargraph.layer import GraphSAGE, link_classification
from stellargraph.ensemble import BaggingEnsemble
from sklearn import preprocessing, feature_extraction, model_selection
from stellargraph import globalvar
from stellargraph import datasets
from IPython.display import display, HTML
%matplotlib inline
Loading the CORA network data¶
(See the “Loading from Pandas” demo for details on how data can be loaded.)
[4]:
dataset = datasets.Cora()
display(HTML(dataset.description))
G, _subjects = dataset.load()
We aim to train a link prediction model, hence we need to prepare the train and test sets of links and the corresponding graphs with those links removed.
We are going to split our input graph into train and test graphs using the EdgeSplitter class in stellargraph.data. We will use the train graph for training the model (a binary classifier that, given two nodes, predicts whether a link between these two nodes should exist or not) and the test graph for evaluating the model’s performance on hold out data.
Each of these graphs will have the same number of nodes as the input graph, but the number of links will differ (be reduced) as some of the links will be removed during each split and used as the positive samples for training/testing the link prediction classifier.
From the original graph G, extract a randomly sampled subset of test edges (true and false citation links) and the reduced graph G_test with the positive test edges removed:
[5]:
# Define an edge splitter on the original graph G:
edge_splitter_test = EdgeSplitter(G)
# Randomly sample a fraction p=0.1 of all positive links, and same number of negative links, from G, and obtain the
# reduced graph G_test with the sampled links removed:
G_test, edge_ids_test, edge_labels_test = edge_splitter_test.train_test_split(
p=0.1, method="global", keep_connected=True, seed=42
)
** Sampled 542 positive and 542 negative edges. **
The reduced graph G_test, together with the test ground truth set of links (edge_ids_test, edge_labels_test), will be used for testing the model.
Now, repeat this procedure to obtain validation data that we are going to use for early stopping in order to prevent overfitting. From the reduced graph G_test, extract a randomly sampled subset of validation edges (true and false citation links) and the reduced graph G_val with the positive validation edges removed.
[6]:
# Define an edge splitter on the reduced graph G_test:
edge_splitter_val = EdgeSplitter(G_test)
# Randomly sample a fraction p=0.1 of all positive links, and same number of negative links, from G_test, and obtain the
# reduced graph G_train with the sampled links removed:
G_val, edge_ids_val, edge_labels_val = edge_splitter_val.train_test_split(
p=0.1, method="global", keep_connected=True, seed=100
)
** Sampled 488 positive and 488 negative edges. **
We repeat this procedure one last time in order to obtain the training data for the model. From the reduced graph G_val, extract a randomly sampled subset of train edges (true and false citation links) and the reduced graph G_train with the positive train edges removed:
[7]:
# Define an edge splitter on the reduced graph G_test:
edge_splitter_train = EdgeSplitter(G_test)
# Randomly sample a fraction p=0.1 of all positive links, and same number of negative links, from G_test, and obtain the
# reduced graph G_train with the sampled links removed:
G_train, edge_ids_train, edge_labels_train = edge_splitter_train.train_test_split(
p=0.1, method="global", keep_connected=True, seed=42
)
** Sampled 488 positive and 488 negative edges. **
G_train, together with the train ground truth set of links (edge_ids_train, edge_labels_train), will be used for training the model.
Summary of G_train and G_test - note that they have the same set of nodes, only differing in their edge sets:
[8]:
print(G_train.info())
StellarGraph: Undirected multigraph
Nodes: 2708, Edges: 4399
Node types:
paper: [2708]
Features: float32 vector, length 1433
Edge types: paper-cites->paper
Edge types:
paper-cites->paper: [4399]
[9]:
print(G_test.info())
StellarGraph: Undirected multigraph
Nodes: 2708, Edges: 4887
Node types:
paper: [2708]
Features: float32 vector, length 1433
Edge types: paper-cites->paper
Edge types:
paper-cites->paper: [4887]
[10]:
print(G_val.info())
StellarGraph: Undirected multigraph
Nodes: 2708, Edges: 4399
Node types:
paper: [2708]
Features: float32 vector, length 1433
Edge types: paper-cites->paper
Edge types:
paper-cites->paper: [4399]
Specify global parameters¶
Here we specify some important parameters that control the type of ensemble model we are going to use. For example, we specify the number of models in the ensemble and the number of predictions per query point per model.
[11]:
n_estimators = 5 # Number of models in the ensemble
n_predictions = 10 # Number of predictions per query point per model
Next, we create link generators for sampling and streaming train and test link examples to the model. The link generators essentially “map” pairs of nodes (paper1, paper2) to the input of GraphSAGE: they take minibatches of node pairs, sample 2-hop subgraphs with (paper1, paper2) head nodes extracted from those pairs, and feed them, together with the corresponding binary labels indicating whether those pairs represent true or false citation links, to the input layer of the GraphSAGE
model, for SGD updates of the model parameters.
Specify the minibatch size (number of node pairs per minibatch) and the number of epochs for training the model:
[12]:
batch_size = 20
epochs = 20
Specify the sizes of 1- and 2-hop neighbour samples for GraphSAGE. Note that the length of num_samples list defines the number of layers/iterations in the GraphSAGE model. In this example, we are defining a 2-layer GraphSAGE model:
[13]:
num_samples = [20, 10]
Create the generators for training¶
For training we create a generator on the G_train graph. The shuffle=True argument is given to the flow method to improve training.
[14]:
generator = GraphSAGELinkGenerator(G_train, batch_size, num_samples)
[15]:
train_gen = generator.flow(edge_ids_train, edge_labels_train, shuffle=True)
At test time we use the G_test graph and don’t specify the shuffle argument (it defaults to False).
[16]:
test_gen = GraphSAGELinkGenerator(G_test, batch_size, num_samples).flow(
edge_ids_test, edge_labels_test
)
[17]:
val_gen = GraphSAGELinkGenerator(G_val, batch_size, num_samples).flow(
edge_ids_val, edge_labels_val
)
Create the base GraphSAGE model¶
Build the model: a 2-layer GraphSAGE model acting as node representation learner, with a link classification layer on concatenated (paper1, paper2) node embeddings.
GraphSAGE part of the model, with hidden layer sizes of 20 for both GraphSAGE layers, a bias term, and no dropout. (Dropout can be switched on by specifying a positive dropout rate, 0 < dropout < 1)
Note that the length of layer_sizes list must be equal to the length of num_samples, as len(num_samples) defines the number of hops (layers) in the GraphSAGE model.
[18]:
layer_sizes = [20, 20]
assert len(layer_sizes) == len(num_samples)
graphsage = GraphSAGE(
layer_sizes=layer_sizes, generator=generator, bias=True, dropout=0.5
)
[19]:
# Build the model and expose the input and output tensors.
x_inp, x_out = graphsage.in_out_tensors()
Final link classification layer that takes a pair of node embeddings produced by GraphSAGE, applies a binary operator to them to produce the corresponding link embedding (ip for inner product; other options for the binary operator can be seen by running a cell with ?link_classification in it), and passes it through a dense layer:
[20]:
prediction = link_classification(
output_dim=1, output_act="relu", edge_embedding_method="ip"
)(x_out)
link_classification: using 'ip' method to combine node embeddings into edge embeddings
Stack the GraphSAGE and prediction layers into a Keras model.
[21]:
base_model = keras.Model(inputs=x_inp, outputs=prediction)
Now we create the ensemble based on base_model we just created.
[22]:
model = BaggingEnsemble(
model=base_model, n_estimators=n_estimators, n_predictions=n_predictions
)
We need to compile the model specifying the optimiser, loss function, and metrics to use.
[23]:
model.compile(
optimizer=keras.optimizers.Adam(lr=1e-3),
loss=keras.losses.binary_crossentropy,
weighted_metrics=["acc"],
)
Evaluate the initial (untrained) ensemble of models on the train and test set:
[24]:
init_train_metrics_mean, init_train_metrics_std = model.evaluate(train_gen)
init_test_metrics_mean, init_test_metrics_std = model.evaluate(test_gen)
print("\nTrain Set Metrics of the initial (untrained) model:")
for name, m, s in zip(
model.metrics_names, init_train_metrics_mean, init_train_metrics_std
):
print("\t{}: {:0.4f}±{:0.4f}".format(name, m, s))
print("\nTest Set Metrics of the initial (untrained) model:")
for name, m, s in zip(model.metrics_names, init_test_metrics_mean, init_test_metrics_std):
print("\t{}: {:0.4f}±{:0.4f}".format(name, m, s))
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
Train Set Metrics of the initial (untrained) model:
loss: 0.6999±0.0411
acc: 0.6063±0.0191
Test Set Metrics of the initial (untrained) model:
loss: 0.7105±0.0467
acc: 0.6152±0.0269
Train the ensemble model¶
We are going to use bootstrap samples of the training dataset to train each model in the ensemble. For this purpose, we need to pass generator, edge_ids_train, and edge_labels_train to the fit method.
Note that training time will vary based on computer speed. Set verbose=1 for reporting of training progress.
[25]:
history = model.fit(
generator=generator,
train_data=edge_ids_train,
train_targets=edge_labels_train,
epochs=epochs,
validation_data=val_gen,
verbose=0,
use_early_stopping=True, # Enable early stopping
early_stopping_monitor="val_acc",
)
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
Plot the training history:
[26]:
sg.utils.plot_history(history)
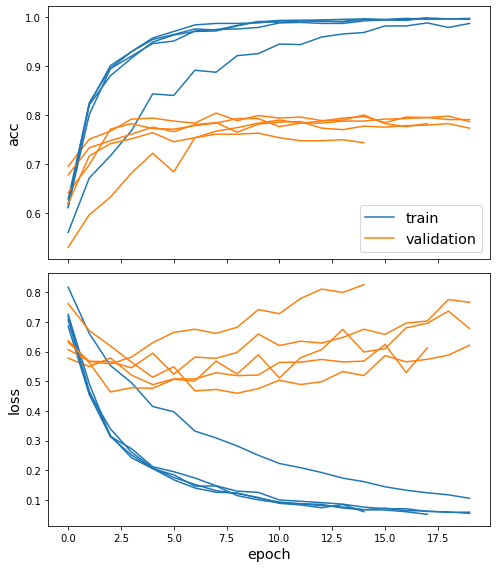
Evaluate the trained model on test citation links. After training the model, performance should be better than before training (shown above):
[27]:
train_metrics_mean, train_metrics_std = model.evaluate(train_gen)
test_metrics_mean, test_metrics_std = model.evaluate(test_gen)
print("\nTrain Set Metrics of the trained model:")
for name, m, s in zip(model.metrics_names, train_metrics_mean, train_metrics_std):
print("\t{}: {:0.4f}±{:0.4f}".format(name, m, s))
print("\nTest Set Metrics of the trained model:")
for name, m, s in zip(model.metrics_names, test_metrics_mean, test_metrics_std):
print("\t{}: {:0.4f}±{:0.4f}".format(name, m, s))
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
['...']
Train Set Metrics of the trained model:
loss: 0.3113±0.0447
acc: 0.9111±0.0099
Test Set Metrics of the trained model:
loss: 0.6903±0.1061
acc: 0.7785±0.0141
Make predictions with the model¶
Now let’s get the predictions for all the edges in the test set.
[28]:
test_predictions = model.predict(generator=test_gen)
These predictions will be the output of the last layer in the model with sigmoid activation.
The array test_predictions has dimensionality \(MxKxNxF\) where \(M\) is the number of estimators in the ensemble (n_estimators); \(K\) is the number of predictions per query point per estimator (n_predictions); \(N\) is the number of query points (len(test_predictions)); and \(F\) is the output dimensionality of the specified layer determined by the shape of the output layer (in this case it is equal to 1 since we are performing binary classification).
[29]:
type(test_predictions), test_predictions.shape
[29]:
(numpy.ndarray, (5, 10, 1084, 1))
For demonstration, we are going to select one of the edges in the test set, and plot the ensemble’s predictions for that edge.
Change the value of selected_query_point (valid values are in the range of 0 to len(test_predictions)) to visualise the results for another test point.
[30]:
selected_query_point = -10
[31]:
# Select the predictios for the point specified by selected_query_point
qp_predictions = test_predictions[:, :, selected_query_point, :]
# The shape should be n_estimators x n_predictions x size_output_layer
qp_predictions.shape
[31]:
(5, 10, 1)
Next, to facilitate plotting the predictions using either a density plot or a box plot, we are going to reshape qp_predictions to \(R\times F\) where \(R\) is equal to \(M\times K\) as above and \(F\) is the output dimensionality of the output layer.
[32]:
qp_predictions = qp_predictions.reshape(
np.product(qp_predictions.shape[0:-1]), qp_predictions.shape[-1]
)
qp_predictions.shape
[32]:
(50, 1)
The model returns the probability of edge, the class to predict. The probability of no edge is just the complement of the latter. Let’s calculate it so that we can plot the distribution of predictions for both outcomes.
[33]:
qp_predictions = np.hstack((qp_predictions, 1.0 - qp_predictions,))
We’d like to assess the ensemble’s confidence in its predictions in order to decide if we can trust them or not. Utilising a box plot, we can visually inspect the ensemble’s distribution of prediction probabilities for a point in the test set.
If the spread of values for the predicted point class is well separated from those of the other class with little overlap then we can be confident that the prediction is correct.
[34]:
correct_label = "Edge"
if edge_labels_test[selected_query_point] == 0:
correct_label = "No Edge"
fig, ax = plt.subplots(figsize=(12, 6))
ax.boxplot(x=qp_predictions)
ax.set_xticklabels(["Edge", "No Edge"])
ax.tick_params(axis="x", rotation=45)
plt.title("Correct label is " + correct_label)
plt.ylabel("Predicted Probability")
plt.xlabel("Class")
[34]:
Text(0.5, 0, 'Class')
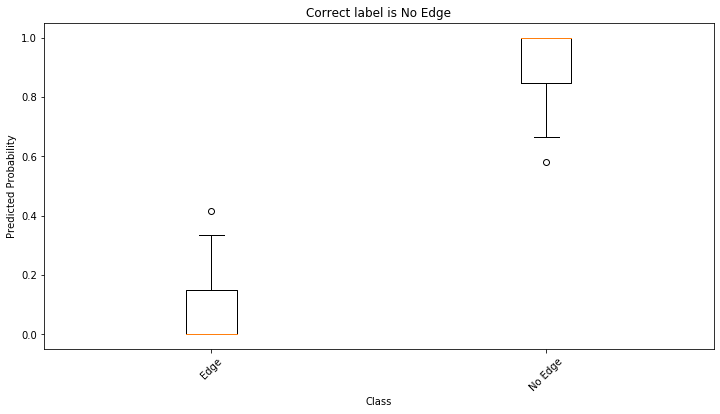
For the selected pair of nodes (query point), the ensemble is not certain as to whether an edge between these two nodes should exist. This can be inferred by the large spread of values as indicated in the above figure.
(Note that due to the stochastic nature of training neural network algorithms, the above conclusion may not be valid if you re-run the notebook; however, the general conclusion that the use of ensemble learning can be used to quantify the model’s uncertainty about its prediction still holds.)
The below image shows an example of the classifier making a correct prediction with higher confidence than the above example. The results is for the setting selected_query_point=0.

Execute this notebook:
![]()
![]() Download locally
Download locally
