Execute this notebook:
![]()
![]() Download locally
Download locally
Node classification with Personalised Propagation of Neural Predictions (PPNP) and Approximate PPNP (APPNP)¶
Import NetworkX and stellargraph:
[3]:
import networkx as nx
import pandas as pd
import numpy as np
import os
from tensorflow import keras
from tensorflow.keras import backend as K
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
import stellargraph as sg
from stellargraph.mapper import FullBatchNodeGenerator
from stellargraph.layer.ppnp import PPNP
from stellargraph.layer.appnp import APPNP
from tensorflow.keras import layers, optimizers, losses, metrics, Model
from sklearn import preprocessing, feature_extraction, model_selection
from stellargraph import datasets
from IPython.display import display, HTML
import matplotlib.pyplot as plt
%matplotlib inline
Loading the CORA network¶
(See the “Loading from Pandas” demo for details on how data can be loaded.)
[4]:
dataset = datasets.Cora()
display(HTML(dataset.description))
G, node_subjects = dataset.load()
[5]:
print(G.info())
StellarGraph: Undirected multigraph
Nodes: 2708, Edges: 5429
Node types:
paper: [2708]
Features: float32 vector, length 1433
Edge types: paper-cites->paper
Edge types:
paper-cites->paper: [5429]
We aim to train a graph-ML model that will predict the “subject” attribute on the nodes. These subjects are one of 7 categories:
[6]:
node_subjects.value_counts().to_frame()
[6]:
| subject | |
|---|---|
| Neural_Networks | 818 |
| Probabilistic_Methods | 426 |
| Genetic_Algorithms | 418 |
| Theory | 351 |
| Case_Based | 298 |
| Reinforcement_Learning | 217 |
| Rule_Learning | 180 |
Splitting the data¶
For machine learning we want to take a subset of the nodes for training, and use the rest for validation and testing. We’ll use scikit-learn again to do this.
Here we’re taking 140 node labels for training, 500 for validation, and the rest for testing.
[7]:
train_subjects, test_subjects = model_selection.train_test_split(
node_subjects, train_size=140, test_size=None, stratify=node_subjects
)
val_subjects, test_subjects = model_selection.train_test_split(
test_subjects, train_size=500, test_size=None, stratify=test_subjects
)
Note using stratified sampling gives the following counts:
[8]:
train_subjects.value_counts().to_frame()
[8]:
| subject | |
|---|---|
| Neural_Networks | 42 |
| Genetic_Algorithms | 22 |
| Probabilistic_Methods | 22 |
| Theory | 18 |
| Case_Based | 16 |
| Reinforcement_Learning | 11 |
| Rule_Learning | 9 |
The training set has class imbalance that might need to be compensated, e.g., via using a weighted cross-entropy loss in model training, with class weights inversely proportional to class support. However, we will ignore the class imbalance in this example, for simplicity.
Converting to numeric arrays¶
For our categorical target, we will use one-hot vectors that will be compared against the model’s soft-max output.
[9]:
target_encoding = preprocessing.LabelBinarizer()
train_targets = target_encoding.fit_transform(train_subjects)
val_targets = target_encoding.transform(val_subjects)
test_targets = target_encoding.transform(test_subjects)
Creating the PPNP model in Keras¶
Now create a StellarGraph object from the NetworkX graph and the node features and targets. It is StellarGraph objects that we use in this library to perform machine learning tasks on.
To feed data from the graph to the Keras model we need a generator. Since PPNP is a full-batch model, we use the FullBatchNodeGenerator class to feed node features and the normalized graph Laplacian matrix to the model.
Specifying the method='ppnp' argument to the FullBatchNodeGenerator will preprocess the adjacency matrix and supply the personalized page rank matrix necessary for PPNP. The personalized page rank matrix is a dense matrix and so sparse=False must be passed to FullBatchNodeGenerator. teleport_probability=0.1 specifies the probability of returning to the starting node in the propagation step as described in the paper (alpha in the paper).
[10]:
generator = FullBatchNodeGenerator(
G, method="ppnp", sparse=False, teleport_probability=0.1
)
For training we map only the training nodes returned from our splitter and the target values.
[11]:
train_gen = generator.flow(train_subjects.index, train_targets)
Now we can specify our machine learning model, we need a few more parameters for this:
the
layer_sizesis a list of hidden feature sizes of each full fully connected layer in the model. In this example we use three fully connected layers with 64,64, and 7 hidden node features at each layer.activationsis a list of activations applied to each layer’s outputdropout=0.5specifies a 50% dropout at each layer.kernel_regularizer=keras.regularizers.l2(0.001)specifies a penalty that prevents the model weights from become too large and helps limit overfitting
Note that the size of the final fully connected layer must be equal to the number of classes you are trying to predict.
We create a PPNP model as follows:
[12]:
ppnp = PPNP(
layer_sizes=[64, 64, train_targets.shape[-1]],
activations=["relu", "relu", "relu"],
generator=generator,
dropout=0.5,
kernel_regularizer=keras.regularizers.l2(0.001),
)
x_inp, x_out = ppnp.in_out_tensors()
predictions = keras.layers.Softmax()(x_out)
Training the model¶
Now let’s create the actual Keras model with the input tensors x_inp and output tensors being the predictions predictions from the final dense layer
[13]:
ppnp_model = Model(inputs=x_inp, outputs=predictions)
ppnp_model.compile(
optimizer=optimizers.Adam(lr=0.01),
loss=losses.categorical_crossentropy,
metrics=["acc"],
)
Train the model, keeping track of its loss and accuracy on the training set, and its generalisation performance on the validation set (we need to create another generator over the validation data for this)
[14]:
val_gen = generator.flow(val_subjects.index, val_targets)
Create callbacks for early stopping (if validation accuracy stops improving) and best model checkpoint saving:
[15]:
if not os.path.isdir("logs"):
os.makedirs("logs")
[16]:
es_callback = EarlyStopping(
monitor="val_acc", patience=50
) # patience is the number of epochs to wait before early stopping in case of no further improvement
mc_callback = ModelCheckpoint(
"logs/best_ppnp_model.h5",
monitor="val_acc",
save_best_only=True,
save_weights_only=True,
)
Train the model
[17]:
history = ppnp_model.fit(
train_gen,
epochs=80,
validation_data=val_gen,
verbose=2,
shuffle=False, # this should be False, since shuffling data means shuffling the whole graph
callbacks=[es_callback, mc_callback],
)
['...']
['...']
Train for 1 steps, validate for 1 steps
Epoch 1/80
1/1 - 1s - loss: 2.1556 - acc: 0.1571 - val_loss: 2.0886 - val_acc: 0.3340
Epoch 2/80
1/1 - 0s - loss: 2.0775 - acc: 0.2643 - val_loss: 2.0250 - val_acc: 0.3020
Epoch 3/80
1/1 - 0s - loss: 2.0350 - acc: 0.3357 - val_loss: 1.9640 - val_acc: 0.3020
Epoch 4/80
1/1 - 0s - loss: 1.9686 - acc: 0.3500 - val_loss: 1.9072 - val_acc: 0.3020
Epoch 5/80
1/1 - 0s - loss: 1.9118 - acc: 0.3286 - val_loss: 1.8519 - val_acc: 0.3020
Epoch 6/80
1/1 - 0s - loss: 1.8614 - acc: 0.3286 - val_loss: 1.7883 - val_acc: 0.3300
Epoch 7/80
1/1 - 0s - loss: 1.8051 - acc: 0.3286 - val_loss: 1.7203 - val_acc: 0.3480
Epoch 8/80
1/1 - 0s - loss: 1.7383 - acc: 0.3786 - val_loss: 1.6565 - val_acc: 0.4700
Epoch 9/80
1/1 - 0s - loss: 1.7872 - acc: 0.3571 - val_loss: 1.6091 - val_acc: 0.6800
Epoch 10/80
1/1 - 0s - loss: 1.6437 - acc: 0.4929 - val_loss: 1.5580 - val_acc: 0.7120
Epoch 11/80
1/1 - 0s - loss: 1.5356 - acc: 0.6286 - val_loss: 1.4868 - val_acc: 0.7180
Epoch 12/80
1/1 - 0s - loss: 1.4670 - acc: 0.6429 - val_loss: 1.4052 - val_acc: 0.7120
Epoch 13/80
1/1 - 0s - loss: 1.4368 - acc: 0.6500 - val_loss: 1.3339 - val_acc: 0.6980
Epoch 14/80
1/1 - 0s - loss: 1.4221 - acc: 0.6357 - val_loss: 1.2761 - val_acc: 0.6920
Epoch 15/80
1/1 - 0s - loss: 1.3478 - acc: 0.6571 - val_loss: 1.2250 - val_acc: 0.6980
Epoch 16/80
1/1 - 0s - loss: 1.2365 - acc: 0.6714 - val_loss: 1.1672 - val_acc: 0.7160
Epoch 17/80
1/1 - 0s - loss: 1.1550 - acc: 0.7214 - val_loss: 1.1331 - val_acc: 0.7140
Epoch 18/80
1/1 - 0s - loss: 1.2100 - acc: 0.7000 - val_loss: 1.1136 - val_acc: 0.7120
Epoch 19/80
1/1 - 0s - loss: 1.1084 - acc: 0.7000 - val_loss: 1.1051 - val_acc: 0.7180
Epoch 20/80
1/1 - 0s - loss: 1.0961 - acc: 0.7143 - val_loss: 1.1169 - val_acc: 0.7140
Epoch 21/80
1/1 - 0s - loss: 1.1314 - acc: 0.7143 - val_loss: 1.1359 - val_acc: 0.7140
Epoch 22/80
1/1 - 0s - loss: 1.1363 - acc: 0.7143 - val_loss: 1.1387 - val_acc: 0.7280
Epoch 23/80
1/1 - 0s - loss: 1.0875 - acc: 0.7429 - val_loss: 1.1233 - val_acc: 0.7500
Epoch 24/80
1/1 - 0s - loss: 1.0232 - acc: 0.7429 - val_loss: 1.0945 - val_acc: 0.7540
Epoch 25/80
1/1 - 0s - loss: 1.0564 - acc: 0.7214 - val_loss: 1.0719 - val_acc: 0.7460
Epoch 26/80
1/1 - 0s - loss: 0.9832 - acc: 0.8143 - val_loss: 1.0603 - val_acc: 0.7540
Epoch 27/80
1/1 - 0s - loss: 0.9897 - acc: 0.7286 - val_loss: 1.0585 - val_acc: 0.7820
Epoch 28/80
1/1 - 0s - loss: 1.0085 - acc: 0.7500 - val_loss: 1.0713 - val_acc: 0.7640
Epoch 29/80
1/1 - 0s - loss: 0.9292 - acc: 0.7500 - val_loss: 1.0938 - val_acc: 0.7440
Epoch 30/80
1/1 - 0s - loss: 0.9356 - acc: 0.7571 - val_loss: 1.1067 - val_acc: 0.7300
Epoch 31/80
1/1 - 0s - loss: 0.8826 - acc: 0.7857 - val_loss: 1.1116 - val_acc: 0.7260
Epoch 32/80
1/1 - 0s - loss: 0.9411 - acc: 0.7643 - val_loss: 1.0897 - val_acc: 0.7380
Epoch 33/80
1/1 - 0s - loss: 0.9439 - acc: 0.7857 - val_loss: 1.0754 - val_acc: 0.7420
Epoch 34/80
1/1 - 0s - loss: 0.8490 - acc: 0.8143 - val_loss: 1.0711 - val_acc: 0.7500
Epoch 35/80
1/1 - 0s - loss: 0.8453 - acc: 0.7857 - val_loss: 1.0632 - val_acc: 0.7500
Epoch 36/80
1/1 - 0s - loss: 0.9247 - acc: 0.8143 - val_loss: 1.0490 - val_acc: 0.7620
Epoch 37/80
1/1 - 0s - loss: 0.8107 - acc: 0.8214 - val_loss: 1.0372 - val_acc: 0.7720
Epoch 38/80
1/1 - 0s - loss: 0.8992 - acc: 0.7714 - val_loss: 1.0296 - val_acc: 0.7840
Epoch 39/80
1/1 - 0s - loss: 0.7891 - acc: 0.8286 - val_loss: 1.0220 - val_acc: 0.7820
Epoch 40/80
1/1 - 0s - loss: 0.9525 - acc: 0.7857 - val_loss: 1.0094 - val_acc: 0.8060
Epoch 41/80
1/1 - 0s - loss: 0.8830 - acc: 0.8286 - val_loss: 1.0159 - val_acc: 0.8120
Epoch 42/80
1/1 - 0s - loss: 0.8916 - acc: 0.8143 - val_loss: 1.0131 - val_acc: 0.8080
Epoch 43/80
1/1 - 0s - loss: 0.8381 - acc: 0.8286 - val_loss: 1.0018 - val_acc: 0.8040
Epoch 44/80
1/1 - 0s - loss: 0.8140 - acc: 0.8143 - val_loss: 0.9910 - val_acc: 0.8080
Epoch 45/80
1/1 - 0s - loss: 0.8264 - acc: 0.8143 - val_loss: 0.9893 - val_acc: 0.8020
Epoch 46/80
1/1 - 0s - loss: 0.8354 - acc: 0.8429 - val_loss: 0.9942 - val_acc: 0.8000
Epoch 47/80
1/1 - 0s - loss: 0.8170 - acc: 0.8429 - val_loss: 0.9960 - val_acc: 0.8040
Epoch 48/80
1/1 - 0s - loss: 0.7662 - acc: 0.8500 - val_loss: 0.9941 - val_acc: 0.8080
Epoch 49/80
1/1 - 0s - loss: 0.8325 - acc: 0.8429 - val_loss: 0.9952 - val_acc: 0.8040
Epoch 50/80
1/1 - 0s - loss: 0.8063 - acc: 0.8643 - val_loss: 0.9960 - val_acc: 0.8020
Epoch 51/80
1/1 - 0s - loss: 0.7980 - acc: 0.8643 - val_loss: 0.9937 - val_acc: 0.8020
Epoch 52/80
1/1 - 0s - loss: 0.7730 - acc: 0.8571 - val_loss: 0.9832 - val_acc: 0.8040
Epoch 53/80
1/1 - 0s - loss: 0.8485 - acc: 0.8500 - val_loss: 0.9706 - val_acc: 0.8100
Epoch 54/80
1/1 - 0s - loss: 0.7297 - acc: 0.8714 - val_loss: 0.9555 - val_acc: 0.8160
Epoch 55/80
1/1 - 0s - loss: 0.8148 - acc: 0.8643 - val_loss: 0.9450 - val_acc: 0.8180
Epoch 56/80
1/1 - 0s - loss: 0.7451 - acc: 0.8857 - val_loss: 0.9424 - val_acc: 0.8140
Epoch 57/80
1/1 - 0s - loss: 0.7683 - acc: 0.8643 - val_loss: 0.9456 - val_acc: 0.8200
Epoch 58/80
1/1 - 0s - loss: 0.7997 - acc: 0.8500 - val_loss: 0.9535 - val_acc: 0.8160
Epoch 59/80
1/1 - 0s - loss: 0.7472 - acc: 0.8714 - val_loss: 0.9661 - val_acc: 0.8080
Epoch 60/80
1/1 - 0s - loss: 0.7238 - acc: 0.8714 - val_loss: 0.9792 - val_acc: 0.8060
Epoch 61/80
1/1 - 0s - loss: 0.7303 - acc: 0.8929 - val_loss: 0.9898 - val_acc: 0.8040
Epoch 62/80
1/1 - 0s - loss: 0.7680 - acc: 0.8714 - val_loss: 0.9973 - val_acc: 0.8060
Epoch 63/80
1/1 - 0s - loss: 0.8879 - acc: 0.8071 - val_loss: 1.0074 - val_acc: 0.8060
Epoch 64/80
1/1 - 0s - loss: 0.7826 - acc: 0.8714 - val_loss: 1.0149 - val_acc: 0.8040
Epoch 65/80
1/1 - 0s - loss: 0.6799 - acc: 0.8786 - val_loss: 1.0084 - val_acc: 0.8040
Epoch 66/80
1/1 - 0s - loss: 0.7639 - acc: 0.8500 - val_loss: 0.9935 - val_acc: 0.8040
Epoch 67/80
1/1 - 0s - loss: 0.7458 - acc: 0.8786 - val_loss: 0.9711 - val_acc: 0.8140
Epoch 68/80
1/1 - 0s - loss: 0.6320 - acc: 0.9000 - val_loss: 0.9564 - val_acc: 0.8180
Epoch 69/80
1/1 - 0s - loss: 0.7241 - acc: 0.8857 - val_loss: 0.9506 - val_acc: 0.8100
Epoch 70/80
1/1 - 0s - loss: 0.7390 - acc: 0.8286 - val_loss: 0.9448 - val_acc: 0.8220
Epoch 71/80
1/1 - 0s - loss: 0.6677 - acc: 0.8643 - val_loss: 0.9432 - val_acc: 0.8260
Epoch 72/80
1/1 - 0s - loss: 0.7128 - acc: 0.8929 - val_loss: 0.9440 - val_acc: 0.8260
Epoch 73/80
1/1 - 0s - loss: 0.6855 - acc: 0.9071 - val_loss: 0.9466 - val_acc: 0.8240
Epoch 74/80
1/1 - 0s - loss: 0.5749 - acc: 0.9071 - val_loss: 0.9514 - val_acc: 0.8160
Epoch 75/80
1/1 - 0s - loss: 0.7657 - acc: 0.8643 - val_loss: 0.9716 - val_acc: 0.8100
Epoch 76/80
1/1 - 0s - loss: 0.6559 - acc: 0.9143 - val_loss: 0.9918 - val_acc: 0.8140
Epoch 77/80
1/1 - 0s - loss: 0.6620 - acc: 0.8929 - val_loss: 1.0184 - val_acc: 0.8100
Epoch 78/80
1/1 - 0s - loss: 0.6626 - acc: 0.8929 - val_loss: 1.0408 - val_acc: 0.8100
Epoch 79/80
1/1 - 0s - loss: 0.6625 - acc: 0.8929 - val_loss: 1.0550 - val_acc: 0.8100
Epoch 80/80
1/1 - 0s - loss: 0.7359 - acc: 0.9000 - val_loss: 1.0519 - val_acc: 0.8140
Plot the training history:
[18]:
sg.utils.plot_history(history)
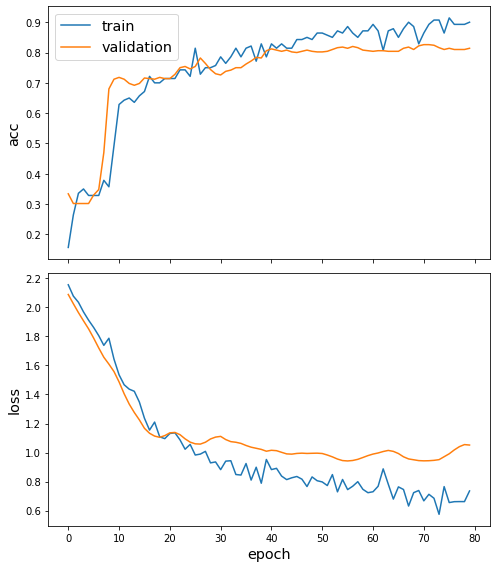
Reload the saved weights of the best model found during the training (according to validation accuracy)
[19]:
ppnp_model.load_weights("logs/best_ppnp_model.h5")
Evaluate the best model on the test set
[20]:
test_gen = generator.flow(test_subjects.index, test_targets)
[21]:
test_metrics = ppnp_model.evaluate(test_gen)
print("\nTest Set Metrics:")
for name, val in zip(ppnp_model.metrics_names, test_metrics):
print("\t{}: {:0.4f}".format(name, val))
['...']
1/1 [==============================] - 0s 15ms/step - loss: 0.8854 - acc: 0.8351
Test Set Metrics:
loss: 0.8854
acc: 0.8351
Using the Approximate PPNP Model¶
Lets repeat the training and testing steps with the APPNP model using the same dataset. The downside of the PPNP is that you have to invert the adjacency matrix - which is time inefficient for large graphs - and store that invert matrix - which is space inefficient. The approximate model avoids this issue by using a clever mathematical trick.
The APPNP model uses the normalized graph Laplacian. To get the normalized graph Laplacian we create a new FullBatchNodeGenerator and set method="gcn". We have the option of choosing sparse=True or sparse=False but will use sparse=True for memory efficiency.
[22]:
generator = FullBatchNodeGenerator(G, method="gcn", sparse=True)
train_gen = generator.flow(train_subjects.index, train_targets)
val_gen = generator.flow(val_subjects.index, val_targets)
test_gen = generator.flow(test_subjects.index, test_targets)
appnp = APPNP(
layer_sizes=[64, 64, train_targets.shape[-1]],
activations=["relu", "relu", "relu"],
bias=True,
generator=generator,
teleport_probability=0.1,
dropout=0.5,
kernel_regularizer=keras.regularizers.l2(0.001),
)
x_inp, x_out = appnp.in_out_tensors()
predictions = keras.layers.Softmax()(x_out)
appnp_model = keras.models.Model(inputs=x_inp, outputs=predictions)
appnp_model.compile(
loss="categorical_crossentropy",
metrics=["acc"],
optimizer=keras.optimizers.Adam(lr=0.01),
)
es_callback = EarlyStopping(
monitor="val_acc", patience=50
) # patience is the number of epochs to wait before early stopping in case of no further improvement
mc_callback = ModelCheckpoint(
"logs/best_appnp_model.h5",
monitor="val_acc",
save_best_only=True,
save_weights_only=True,
)
history = appnp_model.fit(
train_gen,
epochs=120,
validation_data=val_gen,
verbose=2,
shuffle=False, # this should be False, since shuffling data means shuffling the whole graph
callbacks=[es_callback, mc_callback],
)
Using GCN (local pooling) filters...
['...']
['...']
Train for 1 steps, validate for 1 steps
Epoch 1/120
1/1 - 1s - loss: 2.1611 - acc: 0.1571 - val_loss: 2.0960 - val_acc: 0.3500
Epoch 2/120
1/1 - 0s - loss: 2.0830 - acc: 0.3214 - val_loss: 2.0560 - val_acc: 0.3780
Epoch 3/120
1/1 - 0s - loss: 2.0771 - acc: 0.2214 - val_loss: 2.0171 - val_acc: 0.3200
Epoch 4/120
1/1 - 0s - loss: 2.0152 - acc: 0.3286 - val_loss: 1.9767 - val_acc: 0.3040
Epoch 5/120
1/1 - 0s - loss: 1.9555 - acc: 0.3143 - val_loss: 1.9280 - val_acc: 0.3040
Epoch 6/120
1/1 - 0s - loss: 1.9276 - acc: 0.3357 - val_loss: 1.8699 - val_acc: 0.3160
Epoch 7/120
1/1 - 0s - loss: 1.9307 - acc: 0.3500 - val_loss: 1.8084 - val_acc: 0.3820
Epoch 8/120
1/1 - 0s - loss: 1.8068 - acc: 0.4286 - val_loss: 1.7449 - val_acc: 0.5320
Epoch 9/120
1/1 - 0s - loss: 1.7419 - acc: 0.4357 - val_loss: 1.6791 - val_acc: 0.6180
Epoch 10/120
1/1 - 0s - loss: 1.7992 - acc: 0.4429 - val_loss: 1.6142 - val_acc: 0.6160
Epoch 11/120
1/1 - 0s - loss: 1.6373 - acc: 0.5429 - val_loss: 1.5286 - val_acc: 0.6260
Epoch 12/120
1/1 - 0s - loss: 1.6104 - acc: 0.5000 - val_loss: 1.4470 - val_acc: 0.6480
Epoch 13/120
1/1 - 0s - loss: 1.5940 - acc: 0.5000 - val_loss: 1.3990 - val_acc: 0.6360
Epoch 14/120
1/1 - 0s - loss: 1.6000 - acc: 0.5286 - val_loss: 1.3676 - val_acc: 0.6400
Epoch 15/120
1/1 - 0s - loss: 1.4582 - acc: 0.5786 - val_loss: 1.3376 - val_acc: 0.6620
Epoch 16/120
1/1 - 0s - loss: 1.4981 - acc: 0.5643 - val_loss: 1.3105 - val_acc: 0.7040
Epoch 17/120
1/1 - 0s - loss: 1.4196 - acc: 0.6500 - val_loss: 1.2935 - val_acc: 0.7060
Epoch 18/120
1/1 - 0s - loss: 1.4223 - acc: 0.6286 - val_loss: 1.2826 - val_acc: 0.7040
Epoch 19/120
1/1 - 0s - loss: 1.6010 - acc: 0.5786 - val_loss: 1.2728 - val_acc: 0.7060
Epoch 20/120
1/1 - 0s - loss: 1.4398 - acc: 0.7000 - val_loss: 1.2584 - val_acc: 0.7200
Epoch 21/120
1/1 - 0s - loss: 1.3107 - acc: 0.6786 - val_loss: 1.2481 - val_acc: 0.7240
Epoch 22/120
1/1 - 0s - loss: 1.3125 - acc: 0.6714 - val_loss: 1.2400 - val_acc: 0.7180
Epoch 23/120
1/1 - 0s - loss: 1.3205 - acc: 0.6929 - val_loss: 1.2298 - val_acc: 0.7120
Epoch 24/120
1/1 - 0s - loss: 1.1782 - acc: 0.7500 - val_loss: 1.2171 - val_acc: 0.7020
Epoch 25/120
1/1 - 0s - loss: 1.2335 - acc: 0.7286 - val_loss: 1.2071 - val_acc: 0.6980
Epoch 26/120
1/1 - 0s - loss: 1.2707 - acc: 0.6714 - val_loss: 1.1907 - val_acc: 0.6980
Epoch 27/120
1/1 - 0s - loss: 1.2500 - acc: 0.6643 - val_loss: 1.1814 - val_acc: 0.7020
Epoch 28/120
1/1 - 0s - loss: 1.1690 - acc: 0.7500 - val_loss: 1.1774 - val_acc: 0.7040
Epoch 29/120
1/1 - 0s - loss: 1.3786 - acc: 0.7214 - val_loss: 1.1625 - val_acc: 0.7240
Epoch 30/120
1/1 - 0s - loss: 1.2246 - acc: 0.7429 - val_loss: 1.1497 - val_acc: 0.7360
Epoch 31/120
1/1 - 0s - loss: 1.1109 - acc: 0.7929 - val_loss: 1.1388 - val_acc: 0.7440
Epoch 32/120
1/1 - 0s - loss: 1.0982 - acc: 0.7929 - val_loss: 1.1308 - val_acc: 0.7600
Epoch 33/120
1/1 - 0s - loss: 1.0929 - acc: 0.7357 - val_loss: 1.1294 - val_acc: 0.7500
Epoch 34/120
1/1 - 0s - loss: 1.1645 - acc: 0.7429 - val_loss: 1.1390 - val_acc: 0.7360
Epoch 35/120
1/1 - 0s - loss: 1.0615 - acc: 0.7714 - val_loss: 1.1495 - val_acc: 0.7320
Epoch 36/120
1/1 - 0s - loss: 1.1692 - acc: 0.7643 - val_loss: 1.1454 - val_acc: 0.7340
Epoch 37/120
1/1 - 0s - loss: 1.1044 - acc: 0.8000 - val_loss: 1.1329 - val_acc: 0.7460
Epoch 38/120
1/1 - 0s - loss: 1.0422 - acc: 0.7857 - val_loss: 1.1178 - val_acc: 0.7580
Epoch 39/120
1/1 - 0s - loss: 1.0328 - acc: 0.8571 - val_loss: 1.1105 - val_acc: 0.7660
Epoch 40/120
1/1 - 0s - loss: 0.9567 - acc: 0.8357 - val_loss: 1.1098 - val_acc: 0.7680
Epoch 41/120
1/1 - 0s - loss: 0.9312 - acc: 0.8357 - val_loss: 1.1015 - val_acc: 0.7760
Epoch 42/120
1/1 - 0s - loss: 1.2391 - acc: 0.8071 - val_loss: 1.0930 - val_acc: 0.7740
Epoch 43/120
1/1 - 0s - loss: 1.5978 - acc: 0.8000 - val_loss: 1.0912 - val_acc: 0.7700
Epoch 44/120
1/1 - 0s - loss: 1.0150 - acc: 0.8071 - val_loss: 1.1093 - val_acc: 0.7520
Epoch 45/120
1/1 - 0s - loss: 0.9192 - acc: 0.8071 - val_loss: 1.1448 - val_acc: 0.7380
Epoch 46/120
1/1 - 0s - loss: 0.9793 - acc: 0.8071 - val_loss: 1.1717 - val_acc: 0.7380
Epoch 47/120
1/1 - 0s - loss: 1.1117 - acc: 0.7929 - val_loss: 1.1779 - val_acc: 0.7380
Epoch 48/120
1/1 - 0s - loss: 0.9973 - acc: 0.7929 - val_loss: 1.1706 - val_acc: 0.7420
Epoch 49/120
1/1 - 0s - loss: 1.0187 - acc: 0.7929 - val_loss: 1.1559 - val_acc: 0.7500
Epoch 50/120
1/1 - 0s - loss: 0.9383 - acc: 0.8571 - val_loss: 1.1413 - val_acc: 0.7580
Epoch 51/120
1/1 - 0s - loss: 0.9927 - acc: 0.8571 - val_loss: 1.1302 - val_acc: 0.7600
Epoch 52/120
1/1 - 0s - loss: 0.9229 - acc: 0.8571 - val_loss: 1.1256 - val_acc: 0.7660
Epoch 53/120
1/1 - 0s - loss: 1.1314 - acc: 0.7929 - val_loss: 1.1287 - val_acc: 0.7780
Epoch 54/120
1/1 - 0s - loss: 0.9056 - acc: 0.8357 - val_loss: 1.1345 - val_acc: 0.7760
Epoch 55/120
1/1 - 0s - loss: 1.0820 - acc: 0.8286 - val_loss: 1.1394 - val_acc: 0.7760
Epoch 56/120
1/1 - 0s - loss: 0.9782 - acc: 0.8357 - val_loss: 1.1435 - val_acc: 0.7820
Epoch 57/120
1/1 - 0s - loss: 0.9712 - acc: 0.8500 - val_loss: 1.1485 - val_acc: 0.7780
Epoch 58/120
1/1 - 0s - loss: 1.0927 - acc: 0.8071 - val_loss: 1.1563 - val_acc: 0.7740
Epoch 59/120
1/1 - 0s - loss: 1.0473 - acc: 0.8500 - val_loss: 1.1698 - val_acc: 0.7720
Epoch 60/120
1/1 - 0s - loss: 0.9803 - acc: 0.8286 - val_loss: 1.1760 - val_acc: 0.7640
Epoch 61/120
1/1 - 0s - loss: 1.0508 - acc: 0.8286 - val_loss: 1.1723 - val_acc: 0.7640
Epoch 62/120
1/1 - 0s - loss: 0.9952 - acc: 0.8214 - val_loss: 1.1675 - val_acc: 0.7640
Epoch 63/120
1/1 - 0s - loss: 0.8698 - acc: 0.8857 - val_loss: 1.1602 - val_acc: 0.7660
Epoch 64/120
1/1 - 0s - loss: 1.0041 - acc: 0.8500 - val_loss: 1.1508 - val_acc: 0.7700
Epoch 65/120
1/1 - 0s - loss: 0.8682 - acc: 0.8357 - val_loss: 1.1417 - val_acc: 0.7740
Epoch 66/120
1/1 - 0s - loss: 0.8056 - acc: 0.8786 - val_loss: 1.1343 - val_acc: 0.7720
Epoch 67/120
1/1 - 0s - loss: 0.9993 - acc: 0.8214 - val_loss: 1.1314 - val_acc: 0.7660
Epoch 68/120
1/1 - 0s - loss: 0.8606 - acc: 0.8357 - val_loss: 1.1302 - val_acc: 0.7740
Epoch 69/120
1/1 - 0s - loss: 0.9701 - acc: 0.7929 - val_loss: 1.1283 - val_acc: 0.7800
Epoch 70/120
1/1 - 0s - loss: 1.0286 - acc: 0.8286 - val_loss: 1.1265 - val_acc: 0.7740
Epoch 71/120
1/1 - 0s - loss: 0.9034 - acc: 0.8214 - val_loss: 1.1273 - val_acc: 0.7740
Epoch 72/120
1/1 - 0s - loss: 1.0693 - acc: 0.8071 - val_loss: 1.1319 - val_acc: 0.7840
Epoch 73/120
1/1 - 0s - loss: 0.8972 - acc: 0.8214 - val_loss: 1.1418 - val_acc: 0.7840
Epoch 74/120
1/1 - 0s - loss: 0.8502 - acc: 0.8571 - val_loss: 1.1508 - val_acc: 0.7880
Epoch 75/120
1/1 - 0s - loss: 0.9756 - acc: 0.8500 - val_loss: 1.1568 - val_acc: 0.7860
Epoch 76/120
1/1 - 0s - loss: 0.8226 - acc: 0.8714 - val_loss: 1.1593 - val_acc: 0.7880
Epoch 77/120
1/1 - 0s - loss: 0.8669 - acc: 0.8571 - val_loss: 1.1600 - val_acc: 0.7920
Epoch 78/120
1/1 - 0s - loss: 0.8231 - acc: 0.8929 - val_loss: 1.1553 - val_acc: 0.7940
Epoch 79/120
1/1 - 0s - loss: 0.9313 - acc: 0.8214 - val_loss: 1.1475 - val_acc: 0.7980
Epoch 80/120
1/1 - 0s - loss: 0.9309 - acc: 0.8643 - val_loss: 1.1389 - val_acc: 0.7920
Epoch 81/120
1/1 - 0s - loss: 0.9103 - acc: 0.9071 - val_loss: 1.1309 - val_acc: 0.7940
Epoch 82/120
1/1 - 0s - loss: 0.9027 - acc: 0.8714 - val_loss: 1.1249 - val_acc: 0.8060
Epoch 83/120
1/1 - 0s - loss: 0.7483 - acc: 0.8857 - val_loss: 1.1217 - val_acc: 0.7980
Epoch 84/120
1/1 - 0s - loss: 0.7934 - acc: 0.8857 - val_loss: 1.1188 - val_acc: 0.8040
Epoch 85/120
1/1 - 0s - loss: 0.7704 - acc: 0.8929 - val_loss: 1.1172 - val_acc: 0.7960
Epoch 86/120
1/1 - 0s - loss: 0.8442 - acc: 0.8643 - val_loss: 1.1168 - val_acc: 0.7960
Epoch 87/120
1/1 - 0s - loss: 0.7724 - acc: 0.9214 - val_loss: 1.1138 - val_acc: 0.8020
Epoch 88/120
1/1 - 0s - loss: 0.8009 - acc: 0.8929 - val_loss: 1.1145 - val_acc: 0.7960
Epoch 89/120
1/1 - 0s - loss: 0.7859 - acc: 0.8786 - val_loss: 1.1210 - val_acc: 0.7960
Epoch 90/120
1/1 - 0s - loss: 1.0622 - acc: 0.8143 - val_loss: 1.1252 - val_acc: 0.7940
Epoch 91/120
1/1 - 0s - loss: 1.0906 - acc: 0.8571 - val_loss: 1.1266 - val_acc: 0.7940
Epoch 92/120
1/1 - 0s - loss: 0.8647 - acc: 0.8571 - val_loss: 1.1287 - val_acc: 0.7940
Epoch 93/120
1/1 - 0s - loss: 0.9691 - acc: 0.8571 - val_loss: 1.1297 - val_acc: 0.7920
Epoch 94/120
1/1 - 0s - loss: 0.9680 - acc: 0.8214 - val_loss: 1.1307 - val_acc: 0.8080
Epoch 95/120
1/1 - 0s - loss: 0.7526 - acc: 0.8929 - val_loss: 1.1313 - val_acc: 0.8100
Epoch 96/120
1/1 - 0s - loss: 0.8328 - acc: 0.8857 - val_loss: 1.1308 - val_acc: 0.8080
Epoch 97/120
1/1 - 0s - loss: 0.7748 - acc: 0.9000 - val_loss: 1.1352 - val_acc: 0.8040
Epoch 98/120
1/1 - 0s - loss: 0.7760 - acc: 0.9286 - val_loss: 1.1388 - val_acc: 0.7980
Epoch 99/120
1/1 - 0s - loss: 0.8175 - acc: 0.9143 - val_loss: 1.1458 - val_acc: 0.7920
Epoch 100/120
1/1 - 0s - loss: 0.8016 - acc: 0.8786 - val_loss: 1.1541 - val_acc: 0.7860
Epoch 101/120
1/1 - 0s - loss: 0.9525 - acc: 0.8429 - val_loss: 1.1617 - val_acc: 0.7840
Epoch 102/120
1/1 - 0s - loss: 0.9398 - acc: 0.8857 - val_loss: 1.1624 - val_acc: 0.7820
Epoch 103/120
1/1 - 0s - loss: 0.8202 - acc: 0.9357 - val_loss: 1.1559 - val_acc: 0.7740
Epoch 104/120
1/1 - 0s - loss: 0.7174 - acc: 0.9429 - val_loss: 1.1506 - val_acc: 0.7720
Epoch 105/120
1/1 - 0s - loss: 0.7702 - acc: 0.8929 - val_loss: 1.1487 - val_acc: 0.7760
Epoch 106/120
1/1 - 0s - loss: 0.7437 - acc: 0.8929 - val_loss: 1.1464 - val_acc: 0.7700
Epoch 107/120
1/1 - 0s - loss: 0.9028 - acc: 0.9143 - val_loss: 1.1480 - val_acc: 0.7700
Epoch 108/120
1/1 - 0s - loss: 0.8906 - acc: 0.8643 - val_loss: 1.1473 - val_acc: 0.7800
Epoch 109/120
1/1 - 0s - loss: 0.6920 - acc: 0.8929 - val_loss: 1.1385 - val_acc: 0.7820
Epoch 110/120
1/1 - 0s - loss: 0.9391 - acc: 0.8643 - val_loss: 1.1308 - val_acc: 0.7900
Epoch 111/120
1/1 - 0s - loss: 0.8782 - acc: 0.8786 - val_loss: 1.1131 - val_acc: 0.7980
Epoch 112/120
1/1 - 0s - loss: 0.7309 - acc: 0.9071 - val_loss: 1.0996 - val_acc: 0.7960
Epoch 113/120
1/1 - 0s - loss: 0.7774 - acc: 0.9143 - val_loss: 1.0933 - val_acc: 0.8020
Epoch 114/120
1/1 - 0s - loss: 0.7890 - acc: 0.9000 - val_loss: 1.0939 - val_acc: 0.8080
Epoch 115/120
1/1 - 0s - loss: 0.9179 - acc: 0.8786 - val_loss: 1.1045 - val_acc: 0.8040
Epoch 116/120
1/1 - 0s - loss: 0.7260 - acc: 0.9357 - val_loss: 1.1189 - val_acc: 0.8000
Epoch 117/120
1/1 - 0s - loss: 0.7813 - acc: 0.9071 - val_loss: 1.1254 - val_acc: 0.7940
Epoch 118/120
1/1 - 0s - loss: 0.8243 - acc: 0.8929 - val_loss: 1.1271 - val_acc: 0.8040
Epoch 119/120
1/1 - 0s - loss: 0.9089 - acc: 0.8786 - val_loss: 1.1246 - val_acc: 0.8000
Epoch 120/120
1/1 - 0s - loss: 0.8312 - acc: 0.8929 - val_loss: 1.1206 - val_acc: 0.8060
[23]:
sg.utils.plot_history(history)
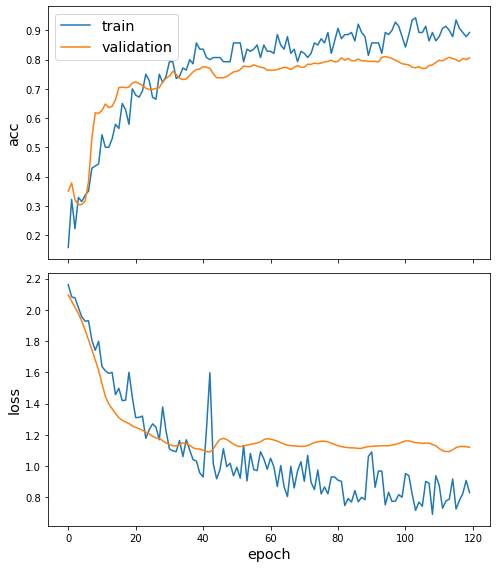
[24]:
appnp_model.load_weights("logs/best_appnp_model.h5")
test_metrics = appnp_model.evaluate(test_gen)
print("\nTest Set Metrics:")
for name, val in zip(appnp_model.metrics_names, test_metrics):
print("\t{}: {:0.4f}".format(name, val))
['...']
1/1 [==============================] - 0s 8ms/step - loss: 1.0577 - acc: 0.8158
Test Set Metrics:
loss: 1.0577
acc: 0.8158
Scalable APPNP Training¶
Now we’re going to exploit the structure of PPNP for scalable training. PPNP consists of a fully-connected neural network followed by a graph propagation step. For each node, the fully-connected network outputs a score for each class and the propagation step basically takes a weighted average of scores of nearby nodes (closer nodes are weighted higher).
Above, we trained the whole network end-to-end which obtains the most accurate results but requires us to load the entire graph onto our GPU memory. This is because we need the entire graph for the propagation step. Unfortunately, this limits the graph size by our GPU memory. To get around this, we can train the fully-connected network separately and once we have a trained fully connected network we can add the graph propagation step. The advantage of this approach is that we can train on batches of node features instead of the entire graph.
The model in the propagation step can be any Keras model trained on node features to predict the target classes. In this example we use a fully connected neural network with bag of word features as input. We could easily swap out the bag of words features for the complete text and replace the fully connected network with a state-of-the-art NLP model (for example BERT [1]), fine-tune the model and propagate its predictions.
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. https://arxiv.org/abs/1810.04805
First we create and train a fully connected model.
[25]:
model = keras.models.Model()
in_layer = layers.Input(shape=(G.node_feature_sizes()["paper"],))
layer = layers.Dropout(0.5)(in_layer)
layer = layers.Dense(64, activation="relu", kernel_regularizer="l2")(layer)
layer = layers.Dropout(0.5)(layer)
layer = layers.Dense(64, activation="relu", kernel_regularizer="l2")(layer)
layer = layers.Dropout(0.5)(layer)
# note the dimension of the output should equal the number of classes to predict!
layer = layers.Dense(train_targets.shape[-1], activation="relu")(layer)
layer = layers.Softmax()(layer)
fully_connected_model = keras.models.Model(inputs=in_layer, outputs=layer)
fully_connected_model.compile(
loss="categorical_crossentropy", metrics=["acc"], optimizer=optimizers.Adam(lr=0.01)
)
# the inputs are just the node features
X_train = G.node_features(train_subjects.index)
X_val = G.node_features(val_subjects.index)
[26]:
es_callback = EarlyStopping(
monitor="val_acc", patience=50
) # patience is the number of epochs to wait before early stopping in case of no further improvement
mc_callback = ModelCheckpoint(
"logs/best_fc_model.h5",
monitor="val_acc",
save_best_only=True,
save_weights_only=True,
)
history = fully_connected_model.fit(
X_train,
train_targets,
validation_data=(X_val, val_targets),
epochs=2000,
batch_size=200,
shuffle=True, # we can shuffle the data here as
callbacks=[es_callback, mc_callback],
) # we're only working with node features
Train on 140 samples, validate on 500 samples
Epoch 1/2000
140/140 [==============================] - 0s 3ms/sample - loss: 3.8201 - acc: 0.1286 - val_loss: 3.2912 - val_acc: 0.3080
Epoch 2/2000
140/140 [==============================] - 0s 83us/sample - loss: 3.2808 - acc: 0.2714 - val_loss: 2.9294 - val_acc: 0.3020
Epoch 3/2000
140/140 [==============================] - 0s 78us/sample - loss: 2.8792 - acc: 0.3214 - val_loss: 2.6845 - val_acc: 0.3020
Epoch 4/2000
140/140 [==============================] - 0s 84us/sample - loss: 2.6692 - acc: 0.3071 - val_loss: 2.5253 - val_acc: 0.3020
Epoch 5/2000
140/140 [==============================] - 0s 92us/sample - loss: 2.4449 - acc: 0.3214 - val_loss: 2.4298 - val_acc: 0.3020
Epoch 6/2000
140/140 [==============================] - 0s 79us/sample - loss: 2.3284 - acc: 0.3143 - val_loss: 2.3773 - val_acc: 0.3020
Epoch 7/2000
140/140 [==============================] - 0s 83us/sample - loss: 2.2412 - acc: 0.3286 - val_loss: 2.3464 - val_acc: 0.3020
Epoch 8/2000
140/140 [==============================] - 0s 103us/sample - loss: 2.2228 - acc: 0.3071 - val_loss: 2.3212 - val_acc: 0.3020
Epoch 9/2000
140/140 [==============================] - 0s 164us/sample - loss: 2.1642 - acc: 0.3429 - val_loss: 2.2951 - val_acc: 0.3220
Epoch 10/2000
140/140 [==============================] - 0s 143us/sample - loss: 2.0998 - acc: 0.3929 - val_loss: 2.2695 - val_acc: 0.3820
Epoch 11/2000
140/140 [==============================] - 0s 141us/sample - loss: 2.0418 - acc: 0.4214 - val_loss: 2.2445 - val_acc: 0.4320
Epoch 12/2000
140/140 [==============================] - 0s 142us/sample - loss: 1.9640 - acc: 0.5143 - val_loss: 2.2181 - val_acc: 0.4480
Epoch 13/2000
140/140 [==============================] - 0s 142us/sample - loss: 1.8945 - acc: 0.5214 - val_loss: 2.1876 - val_acc: 0.4760
Epoch 14/2000
140/140 [==============================] - 0s 151us/sample - loss: 1.8290 - acc: 0.5429 - val_loss: 2.1535 - val_acc: 0.4780
Epoch 15/2000
140/140 [==============================] - 0s 150us/sample - loss: 1.7720 - acc: 0.5786 - val_loss: 2.1225 - val_acc: 0.4800
Epoch 16/2000
140/140 [==============================] - 0s 157us/sample - loss: 1.8089 - acc: 0.5857 - val_loss: 2.0908 - val_acc: 0.4820
Epoch 17/2000
140/140 [==============================] - 0s 157us/sample - loss: 1.6867 - acc: 0.5929 - val_loss: 2.0573 - val_acc: 0.4900
Epoch 18/2000
140/140 [==============================] - 0s 146us/sample - loss: 1.5806 - acc: 0.6286 - val_loss: 2.0274 - val_acc: 0.4940
Epoch 19/2000
140/140 [==============================] - 0s 95us/sample - loss: 1.5333 - acc: 0.6357 - val_loss: 2.0046 - val_acc: 0.4920
Epoch 20/2000
140/140 [==============================] - 0s 95us/sample - loss: 1.4646 - acc: 0.6500 - val_loss: 1.9873 - val_acc: 0.4920
Epoch 21/2000
140/140 [==============================] - 0s 86us/sample - loss: 1.4614 - acc: 0.6500 - val_loss: 1.9709 - val_acc: 0.4940
Epoch 22/2000
140/140 [==============================] - 0s 149us/sample - loss: 1.4018 - acc: 0.7000 - val_loss: 1.9564 - val_acc: 0.5000
Epoch 23/2000
140/140 [==============================] - 0s 143us/sample - loss: 1.3746 - acc: 0.7071 - val_loss: 1.9532 - val_acc: 0.5160
Epoch 24/2000
140/140 [==============================] - 0s 147us/sample - loss: 1.3467 - acc: 0.7143 - val_loss: 1.9540 - val_acc: 0.5240
Epoch 25/2000
140/140 [==============================] - 0s 89us/sample - loss: 1.2373 - acc: 0.8071 - val_loss: 1.9415 - val_acc: 0.5120
Epoch 26/2000
140/140 [==============================] - 0s 94us/sample - loss: 1.3242 - acc: 0.7571 - val_loss: 1.9392 - val_acc: 0.5080
Epoch 27/2000
140/140 [==============================] - 0s 87us/sample - loss: 1.1863 - acc: 0.7857 - val_loss: 1.9469 - val_acc: 0.5080
Epoch 28/2000
140/140 [==============================] - 0s 89us/sample - loss: 1.3267 - acc: 0.7857 - val_loss: 1.9560 - val_acc: 0.4980
Epoch 29/2000
140/140 [==============================] - 0s 82us/sample - loss: 1.1390 - acc: 0.8429 - val_loss: 1.9454 - val_acc: 0.5160
Epoch 30/2000
140/140 [==============================] - 0s 92us/sample - loss: 1.1522 - acc: 0.8429 - val_loss: 1.9369 - val_acc: 0.5240
Epoch 31/2000
140/140 [==============================] - 0s 158us/sample - loss: 1.1971 - acc: 0.7929 - val_loss: 1.9244 - val_acc: 0.5360
Epoch 32/2000
140/140 [==============================] - 0s 88us/sample - loss: 1.1052 - acc: 0.8786 - val_loss: 1.9267 - val_acc: 0.5260
Epoch 33/2000
140/140 [==============================] - 0s 98us/sample - loss: 1.0775 - acc: 0.8786 - val_loss: 1.9390 - val_acc: 0.5320
Epoch 34/2000
140/140 [==============================] - 0s 148us/sample - loss: 1.1779 - acc: 0.8143 - val_loss: 1.9429 - val_acc: 0.5500
Epoch 35/2000
140/140 [==============================] - 0s 155us/sample - loss: 1.1674 - acc: 0.8143 - val_loss: 1.9438 - val_acc: 0.5540
Epoch 36/2000
140/140 [==============================] - 0s 92us/sample - loss: 1.0945 - acc: 0.8714 - val_loss: 1.9487 - val_acc: 0.5520
Epoch 37/2000
140/140 [==============================] - 0s 85us/sample - loss: 1.0334 - acc: 0.9000 - val_loss: 1.9659 - val_acc: 0.5460
Epoch 38/2000
140/140 [==============================] - 0s 90us/sample - loss: 1.1242 - acc: 0.8357 - val_loss: 1.9779 - val_acc: 0.5420
Epoch 39/2000
140/140 [==============================] - 0s 107us/sample - loss: 0.9863 - acc: 0.9429 - val_loss: 1.9859 - val_acc: 0.5420
Epoch 40/2000
140/140 [==============================] - 0s 88us/sample - loss: 1.0593 - acc: 0.9143 - val_loss: 1.9760 - val_acc: 0.5420
Epoch 41/2000
140/140 [==============================] - 0s 107us/sample - loss: 1.0438 - acc: 0.8786 - val_loss: 1.9663 - val_acc: 0.5360
Epoch 42/2000
140/140 [==============================] - 0s 92us/sample - loss: 1.0331 - acc: 0.8857 - val_loss: 1.9657 - val_acc: 0.5500
Epoch 43/2000
140/140 [==============================] - 0s 100us/sample - loss: 1.1313 - acc: 0.8643 - val_loss: 1.9746 - val_acc: 0.5500
Epoch 44/2000
140/140 [==============================] - 0s 94us/sample - loss: 0.9899 - acc: 0.9214 - val_loss: 1.9764 - val_acc: 0.5440
Epoch 45/2000
140/140 [==============================] - 0s 87us/sample - loss: 1.0035 - acc: 0.9214 - val_loss: 1.9694 - val_acc: 0.5500
Epoch 46/2000
140/140 [==============================] - 0s 95us/sample - loss: 1.1105 - acc: 0.8429 - val_loss: 1.9550 - val_acc: 0.5520
Epoch 47/2000
140/140 [==============================] - 0s 156us/sample - loss: 0.9754 - acc: 0.9071 - val_loss: 1.9484 - val_acc: 0.5580
Epoch 48/2000
140/140 [==============================] - 0s 97us/sample - loss: 1.0279 - acc: 0.8857 - val_loss: 1.9500 - val_acc: 0.5520
Epoch 49/2000
140/140 [==============================] - 0s 97us/sample - loss: 1.0529 - acc: 0.8786 - val_loss: 1.9544 - val_acc: 0.5400
Epoch 50/2000
140/140 [==============================] - 0s 105us/sample - loss: 1.1056 - acc: 0.8357 - val_loss: 1.9536 - val_acc: 0.5440
Epoch 51/2000
140/140 [==============================] - 0s 98us/sample - loss: 0.9449 - acc: 0.9357 - val_loss: 1.9526 - val_acc: 0.5320
Epoch 52/2000
140/140 [==============================] - 0s 100us/sample - loss: 0.9428 - acc: 0.9214 - val_loss: 1.9504 - val_acc: 0.5400
Epoch 53/2000
140/140 [==============================] - 0s 112us/sample - loss: 0.9933 - acc: 0.9000 - val_loss: 1.9406 - val_acc: 0.5500
Epoch 54/2000
140/140 [==============================] - 0s 104us/sample - loss: 0.9363 - acc: 0.9429 - val_loss: 1.9353 - val_acc: 0.5520
Epoch 55/2000
140/140 [==============================] - 0s 83us/sample - loss: 1.0300 - acc: 0.8643 - val_loss: 1.9259 - val_acc: 0.5560
Epoch 56/2000
140/140 [==============================] - 0s 152us/sample - loss: 0.9245 - acc: 0.9214 - val_loss: 1.9302 - val_acc: 0.5680
Epoch 57/2000
140/140 [==============================] - 0s 85us/sample - loss: 1.0145 - acc: 0.8929 - val_loss: 1.9363 - val_acc: 0.5660
Epoch 58/2000
140/140 [==============================] - 0s 87us/sample - loss: 0.9671 - acc: 0.8857 - val_loss: 1.9351 - val_acc: 0.5620
Epoch 59/2000
140/140 [==============================] - 0s 103us/sample - loss: 0.9474 - acc: 0.9143 - val_loss: 1.9316 - val_acc: 0.5680
Epoch 60/2000
140/140 [==============================] - 0s 84us/sample - loss: 1.0560 - acc: 0.8500 - val_loss: 1.9190 - val_acc: 0.5620
Epoch 61/2000
140/140 [==============================] - 0s 108us/sample - loss: 0.9253 - acc: 0.9357 - val_loss: 1.9100 - val_acc: 0.5500
Epoch 62/2000
140/140 [==============================] - 0s 89us/sample - loss: 0.9976 - acc: 0.9000 - val_loss: 1.9112 - val_acc: 0.5500
Epoch 63/2000
140/140 [==============================] - 0s 130us/sample - loss: 1.0005 - acc: 0.8857 - val_loss: 1.9208 - val_acc: 0.5300
Epoch 64/2000
140/140 [==============================] - 0s 111us/sample - loss: 0.8937 - acc: 0.9429 - val_loss: 1.9329 - val_acc: 0.5360
Epoch 65/2000
140/140 [==============================] - 0s 95us/sample - loss: 0.9581 - acc: 0.9071 - val_loss: 1.9383 - val_acc: 0.5440
Epoch 66/2000
140/140 [==============================] - 0s 87us/sample - loss: 1.0596 - acc: 0.8643 - val_loss: 1.9442 - val_acc: 0.5380
Epoch 67/2000
140/140 [==============================] - 0s 104us/sample - loss: 0.9023 - acc: 0.9286 - val_loss: 1.9479 - val_acc: 0.5420
Epoch 68/2000
140/140 [==============================] - 0s 92us/sample - loss: 0.9838 - acc: 0.9143 - val_loss: 1.9516 - val_acc: 0.5480
Epoch 69/2000
140/140 [==============================] - 0s 92us/sample - loss: 0.9933 - acc: 0.9000 - val_loss: 1.9460 - val_acc: 0.5420
Epoch 70/2000
140/140 [==============================] - 0s 83us/sample - loss: 0.9406 - acc: 0.9286 - val_loss: 1.9482 - val_acc: 0.5420
Epoch 71/2000
140/140 [==============================] - 0s 99us/sample - loss: 0.8976 - acc: 0.9357 - val_loss: 1.9552 - val_acc: 0.5420
Epoch 72/2000
140/140 [==============================] - 0s 107us/sample - loss: 0.9861 - acc: 0.8929 - val_loss: 1.9647 - val_acc: 0.5140
Epoch 73/2000
140/140 [==============================] - 0s 85us/sample - loss: 0.8325 - acc: 0.9500 - val_loss: 1.9713 - val_acc: 0.5180
Epoch 74/2000
140/140 [==============================] - 0s 99us/sample - loss: 0.8933 - acc: 0.9357 - val_loss: 1.9735 - val_acc: 0.5140
Epoch 75/2000
140/140 [==============================] - 0s 90us/sample - loss: 0.9264 - acc: 0.9000 - val_loss: 1.9686 - val_acc: 0.5100
Epoch 76/2000
140/140 [==============================] - 0s 93us/sample - loss: 0.9116 - acc: 0.9357 - val_loss: 1.9614 - val_acc: 0.5240
Epoch 77/2000
140/140 [==============================] - 0s 88us/sample - loss: 0.9926 - acc: 0.9071 - val_loss: 1.9484 - val_acc: 0.5260
Epoch 78/2000
140/140 [==============================] - 0s 87us/sample - loss: 0.9179 - acc: 0.9286 - val_loss: 1.9387 - val_acc: 0.5220
Epoch 79/2000
140/140 [==============================] - 0s 97us/sample - loss: 0.8961 - acc: 0.9357 - val_loss: 1.9363 - val_acc: 0.5220
Epoch 80/2000
140/140 [==============================] - 0s 89us/sample - loss: 1.0118 - acc: 0.8714 - val_loss: 1.9442 - val_acc: 0.5320
Epoch 81/2000
140/140 [==============================] - 0s 105us/sample - loss: 0.9812 - acc: 0.8857 - val_loss: 1.9578 - val_acc: 0.5320
Epoch 82/2000
140/140 [==============================] - 0s 93us/sample - loss: 0.9034 - acc: 0.9071 - val_loss: 1.9687 - val_acc: 0.5340
Epoch 83/2000
140/140 [==============================] - 0s 96us/sample - loss: 0.9148 - acc: 0.9214 - val_loss: 1.9721 - val_acc: 0.5260
Epoch 84/2000
140/140 [==============================] - 0s 94us/sample - loss: 0.9112 - acc: 0.9214 - val_loss: 1.9743 - val_acc: 0.5300
Epoch 85/2000
140/140 [==============================] - 0s 80us/sample - loss: 0.9514 - acc: 0.9000 - val_loss: 1.9675 - val_acc: 0.5480
Epoch 86/2000
140/140 [==============================] - 0s 98us/sample - loss: 1.0306 - acc: 0.9071 - val_loss: 1.9527 - val_acc: 0.5480
Epoch 87/2000
140/140 [==============================] - 0s 85us/sample - loss: 0.9282 - acc: 0.9357 - val_loss: 1.9466 - val_acc: 0.5500
Epoch 88/2000
140/140 [==============================] - 0s 90us/sample - loss: 0.9865 - acc: 0.9000 - val_loss: 1.9465 - val_acc: 0.5560
Epoch 89/2000
140/140 [==============================] - 0s 93us/sample - loss: 0.9454 - acc: 0.9286 - val_loss: 1.9484 - val_acc: 0.5520
Epoch 90/2000
140/140 [==============================] - 0s 86us/sample - loss: 0.9295 - acc: 0.9286 - val_loss: 1.9416 - val_acc: 0.5620
Epoch 91/2000
140/140 [==============================] - 0s 152us/sample - loss: 1.0591 - acc: 0.8500 - val_loss: 1.9329 - val_acc: 0.5700
Epoch 92/2000
140/140 [==============================] - 0s 85us/sample - loss: 0.9447 - acc: 0.8857 - val_loss: 1.9279 - val_acc: 0.5560
Epoch 93/2000
140/140 [==============================] - 0s 92us/sample - loss: 0.9101 - acc: 0.9357 - val_loss: 1.9303 - val_acc: 0.5500
Epoch 94/2000
140/140 [==============================] - 0s 87us/sample - loss: 0.8793 - acc: 0.9500 - val_loss: 1.9392 - val_acc: 0.5500
Epoch 95/2000
140/140 [==============================] - 0s 91us/sample - loss: 0.8725 - acc: 0.9571 - val_loss: 1.9488 - val_acc: 0.5600
Epoch 96/2000
140/140 [==============================] - 0s 86us/sample - loss: 0.9350 - acc: 0.9071 - val_loss: 1.9486 - val_acc: 0.5680
Epoch 97/2000
140/140 [==============================] - 0s 78us/sample - loss: 0.8988 - acc: 0.9357 - val_loss: 1.9448 - val_acc: 0.5700
Epoch 98/2000
140/140 [==============================] - 0s 94us/sample - loss: 0.9016 - acc: 0.9357 - val_loss: 1.9352 - val_acc: 0.5500
Epoch 99/2000
140/140 [==============================] - 0s 93us/sample - loss: 0.8885 - acc: 0.9357 - val_loss: 1.9327 - val_acc: 0.5420
Epoch 100/2000
140/140 [==============================] - 0s 105us/sample - loss: 0.9253 - acc: 0.9214 - val_loss: 1.9366 - val_acc: 0.5360
Epoch 101/2000
140/140 [==============================] - 0s 77us/sample - loss: 0.8266 - acc: 0.9714 - val_loss: 1.9448 - val_acc: 0.5280
Epoch 102/2000
140/140 [==============================] - 0s 85us/sample - loss: 0.8642 - acc: 0.9357 - val_loss: 1.9489 - val_acc: 0.5220
Epoch 103/2000
140/140 [==============================] - 0s 90us/sample - loss: 0.9301 - acc: 0.9000 - val_loss: 1.9628 - val_acc: 0.5280
Epoch 104/2000
140/140 [==============================] - 0s 81us/sample - loss: 0.8503 - acc: 0.9214 - val_loss: 1.9635 - val_acc: 0.5380
Epoch 105/2000
140/140 [==============================] - 0s 104us/sample - loss: 0.8412 - acc: 0.9357 - val_loss: 1.9618 - val_acc: 0.5440
Epoch 106/2000
140/140 [==============================] - 0s 96us/sample - loss: 0.9407 - acc: 0.9143 - val_loss: 1.9454 - val_acc: 0.5380
Epoch 107/2000
140/140 [==============================] - 0s 83us/sample - loss: 0.9286 - acc: 0.9071 - val_loss: 1.9270 - val_acc: 0.5200
Epoch 108/2000
140/140 [==============================] - 0s 94us/sample - loss: 0.9219 - acc: 0.9071 - val_loss: 1.9152 - val_acc: 0.5260
Epoch 109/2000
140/140 [==============================] - 0s 81us/sample - loss: 0.8760 - acc: 0.9286 - val_loss: 1.9144 - val_acc: 0.5260
Epoch 110/2000
140/140 [==============================] - 0s 95us/sample - loss: 0.8704 - acc: 0.9357 - val_loss: 1.9226 - val_acc: 0.5320
Epoch 111/2000
140/140 [==============================] - 0s 85us/sample - loss: 0.9061 - acc: 0.9143 - val_loss: 1.9322 - val_acc: 0.5380
Epoch 112/2000
140/140 [==============================] - 0s 88us/sample - loss: 0.9191 - acc: 0.9286 - val_loss: 1.9459 - val_acc: 0.5400
Epoch 113/2000
140/140 [==============================] - 0s 95us/sample - loss: 0.9249 - acc: 0.9214 - val_loss: 1.9543 - val_acc: 0.5480
Epoch 114/2000
140/140 [==============================] - 0s 98us/sample - loss: 0.9360 - acc: 0.9071 - val_loss: 1.9570 - val_acc: 0.5420
Epoch 115/2000
140/140 [==============================] - 0s 100us/sample - loss: 0.8688 - acc: 0.9286 - val_loss: 1.9520 - val_acc: 0.5340
Epoch 116/2000
140/140 [==============================] - 0s 86us/sample - loss: 0.8182 - acc: 0.9500 - val_loss: 1.9471 - val_acc: 0.5340
Epoch 117/2000
140/140 [==============================] - 0s 100us/sample - loss: 0.9340 - acc: 0.9000 - val_loss: 1.9407 - val_acc: 0.5480
Epoch 118/2000
140/140 [==============================] - 0s 93us/sample - loss: 0.8599 - acc: 0.9500 - val_loss: 1.9478 - val_acc: 0.5400
Epoch 119/2000
140/140 [==============================] - 0s 94us/sample - loss: 0.9156 - acc: 0.9214 - val_loss: 1.9593 - val_acc: 0.5480
Epoch 120/2000
140/140 [==============================] - 0s 93us/sample - loss: 0.9137 - acc: 0.9214 - val_loss: 1.9656 - val_acc: 0.5420
Epoch 121/2000
140/140 [==============================] - 0s 86us/sample - loss: 1.0899 - acc: 0.8643 - val_loss: 1.9542 - val_acc: 0.5580
Epoch 122/2000
140/140 [==============================] - 0s 92us/sample - loss: 0.8300 - acc: 0.9571 - val_loss: 1.9495 - val_acc: 0.5520
Epoch 123/2000
140/140 [==============================] - 0s 81us/sample - loss: 0.9260 - acc: 0.9143 - val_loss: 1.9414 - val_acc: 0.5480
Epoch 124/2000
140/140 [==============================] - 0s 88us/sample - loss: 0.9196 - acc: 0.9000 - val_loss: 1.9379 - val_acc: 0.5380
Epoch 125/2000
140/140 [==============================] - 0s 95us/sample - loss: 0.9593 - acc: 0.9143 - val_loss: 1.9339 - val_acc: 0.5580
Epoch 126/2000
140/140 [==============================] - 0s 86us/sample - loss: 0.9930 - acc: 0.9000 - val_loss: 1.9367 - val_acc: 0.5540
Epoch 127/2000
140/140 [==============================] - 0s 91us/sample - loss: 0.8355 - acc: 0.9500 - val_loss: 1.9413 - val_acc: 0.5560
Epoch 128/2000
140/140 [==============================] - 0s 87us/sample - loss: 0.9429 - acc: 0.9000 - val_loss: 1.9489 - val_acc: 0.5460
Epoch 129/2000
140/140 [==============================] - 0s 87us/sample - loss: 0.8404 - acc: 0.9643 - val_loss: 1.9557 - val_acc: 0.5440
Epoch 130/2000
140/140 [==============================] - 0s 81us/sample - loss: 0.9001 - acc: 0.9143 - val_loss: 1.9592 - val_acc: 0.5560
Epoch 131/2000
140/140 [==============================] - 0s 97us/sample - loss: 0.9761 - acc: 0.9000 - val_loss: 1.9608 - val_acc: 0.5500
Epoch 132/2000
140/140 [==============================] - 0s 113us/sample - loss: 1.0063 - acc: 0.8929 - val_loss: 1.9530 - val_acc: 0.5580
Epoch 133/2000
140/140 [==============================] - 0s 88us/sample - loss: 0.8973 - acc: 0.9357 - val_loss: 1.9471 - val_acc: 0.5580
Epoch 134/2000
140/140 [==============================] - 0s 148us/sample - loss: 0.9566 - acc: 0.9143 - val_loss: 1.9413 - val_acc: 0.5780
Epoch 135/2000
140/140 [==============================] - 0s 95us/sample - loss: 0.8656 - acc: 0.9286 - val_loss: 1.9347 - val_acc: 0.5660
Epoch 136/2000
140/140 [==============================] - 0s 107us/sample - loss: 0.8765 - acc: 0.9214 - val_loss: 1.9258 - val_acc: 0.5760
Epoch 137/2000
140/140 [==============================] - 0s 84us/sample - loss: 0.8905 - acc: 0.9071 - val_loss: 1.9186 - val_acc: 0.5740
Epoch 138/2000
140/140 [==============================] - 0s 90us/sample - loss: 0.9537 - acc: 0.8714 - val_loss: 1.9161 - val_acc: 0.5580
Epoch 139/2000
140/140 [==============================] - 0s 82us/sample - loss: 0.9438 - acc: 0.9000 - val_loss: 1.9166 - val_acc: 0.5500
Epoch 140/2000
140/140 [==============================] - 0s 100us/sample - loss: 0.8830 - acc: 0.9357 - val_loss: 1.9138 - val_acc: 0.5560
Epoch 141/2000
140/140 [==============================] - 0s 104us/sample - loss: 0.9715 - acc: 0.8857 - val_loss: 1.9105 - val_acc: 0.5540
Epoch 142/2000
140/140 [==============================] - 0s 93us/sample - loss: 0.8759 - acc: 0.9357 - val_loss: 1.9025 - val_acc: 0.5620
Epoch 143/2000
140/140 [==============================] - 0s 105us/sample - loss: 0.8466 - acc: 0.9429 - val_loss: 1.8982 - val_acc: 0.5600
Epoch 144/2000
140/140 [==============================] - 0s 103us/sample - loss: 0.8608 - acc: 0.9429 - val_loss: 1.8937 - val_acc: 0.5640
Epoch 145/2000
140/140 [==============================] - 0s 109us/sample - loss: 0.9898 - acc: 0.8643 - val_loss: 1.8865 - val_acc: 0.5680
Epoch 146/2000
140/140 [==============================] - 0s 100us/sample - loss: 0.9417 - acc: 0.9000 - val_loss: 1.8858 - val_acc: 0.5640
Epoch 147/2000
140/140 [==============================] - 0s 107us/sample - loss: 0.9533 - acc: 0.9071 - val_loss: 1.8988 - val_acc: 0.5540
Epoch 148/2000
140/140 [==============================] - 0s 92us/sample - loss: 0.9109 - acc: 0.9143 - val_loss: 1.8929 - val_acc: 0.5500
Epoch 149/2000
140/140 [==============================] - 0s 91us/sample - loss: 0.9624 - acc: 0.9000 - val_loss: 1.8700 - val_acc: 0.5600
Epoch 150/2000
140/140 [==============================] - 0s 100us/sample - loss: 0.8296 - acc: 0.9571 - val_loss: 1.8520 - val_acc: 0.5660
Epoch 151/2000
140/140 [==============================] - 0s 159us/sample - loss: 0.9041 - acc: 0.9071 - val_loss: 1.8461 - val_acc: 0.5860
Epoch 152/2000
140/140 [==============================] - 0s 85us/sample - loss: 0.8742 - acc: 0.9357 - val_loss: 1.8487 - val_acc: 0.5720
Epoch 153/2000
140/140 [==============================] - 0s 87us/sample - loss: 0.8634 - acc: 0.9214 - val_loss: 1.8508 - val_acc: 0.5680
Epoch 154/2000
140/140 [==============================] - 0s 97us/sample - loss: 0.8694 - acc: 0.9214 - val_loss: 1.8477 - val_acc: 0.5740
Epoch 155/2000
140/140 [==============================] - 0s 88us/sample - loss: 0.8465 - acc: 0.9357 - val_loss: 1.8468 - val_acc: 0.5780
Epoch 156/2000
140/140 [==============================] - 0s 97us/sample - loss: 0.8932 - acc: 0.9000 - val_loss: 1.8469 - val_acc: 0.5700
Epoch 157/2000
140/140 [==============================] - 0s 109us/sample - loss: 0.8758 - acc: 0.9286 - val_loss: 1.8585 - val_acc: 0.5560
Epoch 158/2000
140/140 [==============================] - 0s 116us/sample - loss: 0.8477 - acc: 0.9571 - val_loss: 1.8982 - val_acc: 0.5660
Epoch 159/2000
140/140 [==============================] - 0s 81us/sample - loss: 0.9012 - acc: 0.9214 - val_loss: 1.9359 - val_acc: 0.5520
Epoch 160/2000
140/140 [==============================] - 0s 108us/sample - loss: 0.9814 - acc: 0.9000 - val_loss: 1.9290 - val_acc: 0.5480
Epoch 161/2000
140/140 [==============================] - 0s 87us/sample - loss: 0.8479 - acc: 0.9500 - val_loss: 1.9168 - val_acc: 0.5440
Epoch 162/2000
140/140 [==============================] - 0s 74us/sample - loss: 0.9104 - acc: 0.9214 - val_loss: 1.9056 - val_acc: 0.5520
Epoch 163/2000
140/140 [==============================] - 0s 96us/sample - loss: 0.9247 - acc: 0.9214 - val_loss: 1.9101 - val_acc: 0.5560
Epoch 164/2000
140/140 [==============================] - 0s 92us/sample - loss: 0.8298 - acc: 0.9500 - val_loss: 1.9230 - val_acc: 0.5560
Epoch 165/2000
140/140 [==============================] - 0s 89us/sample - loss: 0.9262 - acc: 0.9071 - val_loss: 1.9357 - val_acc: 0.5620
Epoch 166/2000
140/140 [==============================] - 0s 92us/sample - loss: 0.8744 - acc: 0.9214 - val_loss: 1.9459 - val_acc: 0.5640
Epoch 167/2000
140/140 [==============================] - 0s 100us/sample - loss: 0.9255 - acc: 0.9143 - val_loss: 1.9505 - val_acc: 0.5600
Epoch 168/2000
140/140 [==============================] - 0s 99us/sample - loss: 0.8452 - acc: 0.9429 - val_loss: 1.9515 - val_acc: 0.5580
Epoch 169/2000
140/140 [==============================] - 0s 87us/sample - loss: 0.8825 - acc: 0.9214 - val_loss: 1.9397 - val_acc: 0.5520
Epoch 170/2000
140/140 [==============================] - 0s 103us/sample - loss: 0.9308 - acc: 0.9000 - val_loss: 1.9303 - val_acc: 0.5580
Epoch 171/2000
140/140 [==============================] - 0s 85us/sample - loss: 0.9189 - acc: 0.9214 - val_loss: 1.9237 - val_acc: 0.5620
Epoch 172/2000
140/140 [==============================] - 0s 93us/sample - loss: 0.9386 - acc: 0.9143 - val_loss: 1.9159 - val_acc: 0.5520
Epoch 173/2000
140/140 [==============================] - 0s 94us/sample - loss: 0.9751 - acc: 0.8786 - val_loss: 1.9132 - val_acc: 0.5540
Epoch 174/2000
140/140 [==============================] - 0s 96us/sample - loss: 0.9459 - acc: 0.8929 - val_loss: 1.9179 - val_acc: 0.5580
Epoch 175/2000
140/140 [==============================] - 0s 91us/sample - loss: 1.0002 - acc: 0.8714 - val_loss: 1.9227 - val_acc: 0.5480
Epoch 176/2000
140/140 [==============================] - 0s 85us/sample - loss: 0.9078 - acc: 0.9071 - val_loss: 1.9332 - val_acc: 0.5380
Epoch 177/2000
140/140 [==============================] - 0s 98us/sample - loss: 0.8872 - acc: 0.9214 - val_loss: 1.9514 - val_acc: 0.5320
Epoch 178/2000
140/140 [==============================] - 0s 90us/sample - loss: 0.8750 - acc: 0.9500 - val_loss: 1.9614 - val_acc: 0.5260
Epoch 179/2000
140/140 [==============================] - 0s 88us/sample - loss: 0.9659 - acc: 0.9071 - val_loss: 1.9632 - val_acc: 0.5240
Epoch 180/2000
140/140 [==============================] - 0s 97us/sample - loss: 0.9674 - acc: 0.9000 - val_loss: 1.9554 - val_acc: 0.5300
Epoch 181/2000
140/140 [==============================] - 0s 87us/sample - loss: 1.0248 - acc: 0.8857 - val_loss: 1.9430 - val_acc: 0.5380
Epoch 182/2000
140/140 [==============================] - 0s 84us/sample - loss: 0.8888 - acc: 0.9357 - val_loss: 1.9356 - val_acc: 0.5460
Epoch 183/2000
140/140 [==============================] - 0s 88us/sample - loss: 0.9461 - acc: 0.9214 - val_loss: 1.9399 - val_acc: 0.5380
Epoch 184/2000
140/140 [==============================] - 0s 94us/sample - loss: 1.0256 - acc: 0.8857 - val_loss: 1.9492 - val_acc: 0.5380
Epoch 185/2000
140/140 [==============================] - 0s 92us/sample - loss: 0.9040 - acc: 0.9143 - val_loss: 1.9593 - val_acc: 0.5320
Epoch 186/2000
140/140 [==============================] - 0s 88us/sample - loss: 0.9038 - acc: 0.9214 - val_loss: 1.9628 - val_acc: 0.5300
Epoch 187/2000
140/140 [==============================] - 0s 93us/sample - loss: 0.9496 - acc: 0.9286 - val_loss: 1.9648 - val_acc: 0.5300
Epoch 188/2000
140/140 [==============================] - 0s 87us/sample - loss: 0.9602 - acc: 0.8929 - val_loss: 1.9651 - val_acc: 0.5440
Epoch 189/2000
140/140 [==============================] - 0s 84us/sample - loss: 0.8971 - acc: 0.9214 - val_loss: 1.9638 - val_acc: 0.5400
Epoch 190/2000
140/140 [==============================] - 0s 85us/sample - loss: 0.8522 - acc: 0.9357 - val_loss: 1.9591 - val_acc: 0.5380
Epoch 191/2000
140/140 [==============================] - 0s 87us/sample - loss: 0.9650 - acc: 0.9143 - val_loss: 1.9527 - val_acc: 0.5340
Epoch 192/2000
140/140 [==============================] - 0s 81us/sample - loss: 1.0122 - acc: 0.8929 - val_loss: 1.9389 - val_acc: 0.5340
Epoch 193/2000
140/140 [==============================] - 0s 88us/sample - loss: 0.9168 - acc: 0.9286 - val_loss: 1.9256 - val_acc: 0.5540
Epoch 194/2000
140/140 [==============================] - 0s 82us/sample - loss: 0.9403 - acc: 0.9000 - val_loss: 1.9204 - val_acc: 0.5600
Epoch 195/2000
140/140 [==============================] - 0s 87us/sample - loss: 0.9763 - acc: 0.9071 - val_loss: 1.9203 - val_acc: 0.5700
Epoch 196/2000
140/140 [==============================] - 0s 88us/sample - loss: 0.9084 - acc: 0.9286 - val_loss: 1.9263 - val_acc: 0.5660
Epoch 197/2000
140/140 [==============================] - 0s 112us/sample - loss: 0.9424 - acc: 0.9000 - val_loss: 1.9334 - val_acc: 0.5620
Epoch 198/2000
140/140 [==============================] - 0s 92us/sample - loss: 0.8912 - acc: 0.9286 - val_loss: 1.9355 - val_acc: 0.5540
Epoch 199/2000
140/140 [==============================] - 0s 81us/sample - loss: 0.9526 - acc: 0.8929 - val_loss: 1.9298 - val_acc: 0.5480
Epoch 200/2000
140/140 [==============================] - 0s 89us/sample - loss: 0.8537 - acc: 0.9643 - val_loss: 1.9241 - val_acc: 0.5540
Epoch 201/2000
140/140 [==============================] - 0s 92us/sample - loss: 0.9466 - acc: 0.8929 - val_loss: 1.9094 - val_acc: 0.5520
By itself the fully connected model only gets ~60% accuracy on the test set.
[27]:
X_test = G.node_features(test_subjects.index)
fully_connected_model.load_weights("logs/best_fc_model.h5")
test_metrics = fully_connected_model.evaluate(X_test, test_targets, verbose=2)
print("\nTest Set Metrics:")
for name, val in zip(fully_connected_model.metrics_names, test_metrics):
print("\t{}: {:0.4f}".format(name, val))
2068/2068 - 0s - loss: 1.8196 - acc: 0.5793
Test Set Metrics:
loss: 1.8196
acc: 0.5793
Now we propagate the fully connected network - no extra training required and we can re-use the APPNP object we’ve already created. First we create an intermediate fully connected model without the softmax layer, this is to avoid propagating the softmax layer which may cause issues with further training. We then propagate this intermediate network.
[28]:
intermediate_model = Model(
inputs=fully_connected_model.inputs, outputs=fully_connected_model.layers[-2].output
)
x_inp, x_out = appnp.propagate_model(intermediate_model)
predictions = keras.layers.Softmax()(x_out)
propagated_model = keras.models.Model(inputs=x_inp, outputs=predictions)
propagated_model.compile(
loss="categorical_crossentropy",
metrics=["acc"],
optimizer=keras.optimizers.Adam(lr=0.01),
)
Our accuracy is better than the fully connected network by itself but less than end-to-end trained PPNP and APPNP.
Note that this is partially because 140 data points isn’t sufficient for the fully connected model to achieve optimal performance. As the number of training nodes increases the performance gap shrinks.
[29]:
test_metrics = propagated_model.evaluate(test_gen)
print("\nTest Set Metrics:")
for name, val in zip(propagated_model.metrics_names, test_metrics):
print("\t{}: {:0.4f}".format(name, val))
['...']
1/1 [==============================] - 0s 208ms/step - loss: 1.6038 - acc: 0.7273
Test Set Metrics:
loss: 1.6038
acc: 0.7273
Making predictions with the model¶
Now let’s get the predictions for all nodes.
[30]:
all_nodes = node_subjects.index
all_gen = generator.flow(all_nodes)
all_predictions = propagated_model.predict(all_gen)
These predictions will be the output of the softmax layer, so to get final categories we’ll use the inverse_transform method of our target attribute specification to turn these values back to the original categories.
Note that for full-batch methods the batch size is 1 and the predictions have shape \((1, N_{nodes}, N_{classes})\) so we remove the batch dimension to obtain predictions of shape \((N_{nodes}, N_{classes})\) using the NumPy squeeze method.
[31]:
node_predictions = target_encoding.inverse_transform(all_predictions.squeeze())
Let’s have a look at a few predictions after training the model:
[32]:
df = pd.DataFrame({"Predicted": node_predictions, "True": node_subjects})
df.head(20)
[32]:
| Predicted | True | |
|---|---|---|
| 31336 | Probabilistic_Methods | Neural_Networks |
| 1061127 | Theory | Rule_Learning |
| 1106406 | Reinforcement_Learning | Reinforcement_Learning |
| 13195 | Genetic_Algorithms | Reinforcement_Learning |
| 37879 | Probabilistic_Methods | Probabilistic_Methods |
| 1126012 | Genetic_Algorithms | Probabilistic_Methods |
| 1107140 | Case_Based | Theory |
| 1102850 | Neural_Networks | Neural_Networks |
| 31349 | Probabilistic_Methods | Neural_Networks |
| 1106418 | Theory | Theory |
| 1123188 | Neural_Networks | Neural_Networks |
| 1128990 | Genetic_Algorithms | Genetic_Algorithms |
| 109323 | Probabilistic_Methods | Probabilistic_Methods |
| 217139 | Case_Based | Case_Based |
| 31353 | Probabilistic_Methods | Neural_Networks |
| 32083 | Neural_Networks | Neural_Networks |
| 1126029 | Neural_Networks | Reinforcement_Learning |
| 1118017 | Neural_Networks | Neural_Networks |
| 49482 | Neural_Networks | Neural_Networks |
| 753265 | Neural_Networks | Neural_Networks |
Now we have an accurate model that can handle large graphs.
Execute this notebook:
![]()
![]() Download locally
Download locally
