Continuous-Time Dynamic Network Embeddings¶
Reference Paper: http://ryanrossi.com/pubs/nguyen-et-al-WWW18-BigNet.pdf
This is a demo of StellarGraph’s implementation of Continuous-Time Dynamic Network Embeddings. The steps outlined in this notebook show how time respecting random walks can be obtained from a graph containing time information on edges, and how these walks can be used to generate network embeddings for a link prediction task.
We compare the embeddings learnt from temporal walks with non-temporal walks in this demo.
Run the master version of this notebook: |
[1]:
# install StellarGraph if running on Google Colab
import sys
if 'google.colab' in sys.modules:
%pip install -q stellargraph[demos]==1.0.0rc1
[2]:
# verify that we're using the correct version of StellarGraph for this notebook
import stellargraph as sg
try:
sg.utils.validate_notebook_version("1.0.0rc1")
except AttributeError:
raise ValueError(
f"This notebook requires StellarGraph version 1.0.0rc1, but a different version {sg.__version__} is installed. Please see <https://github.com/stellargraph/stellargraph/issues/1172>."
) from None
[3]:
import numpy as np
import pandas as pd
import random
import matplotlib.pyplot as plt
from IPython.display import display, HTML
from sklearn.manifold import TSNE
from sklearn.model_selection import train_test_split
from stellargraph import StellarGraph
from stellargraph.datasets import IAEnronEmployees
%matplotlib inline
Dataset¶
The dataset used in this demo is called enron-ia-employees, available in Network Repository: http://networkrepository.com/ia-enron-employees.php
[4]:
dataset = IAEnronEmployees()
display(HTML(dataset.description))
full_graph, edges = dataset.load()
Split edges¶
We want to split the edges into parts that can be used for our link prediction task: * the oldest edges are used to create the graph structure * the recent edges are what we are interested in predicting - we randomly split this part further into training and test sets.
[5]:
# subset of edges to split
train_subset = 0.25
test_subset = 0.25
# number of edges to be kept in the graph
num_edges_graph = int(len(edges) * (1 - train_subset))
# keep older edges in graph, and predict more recent edges
edges_graph = edges[:num_edges_graph]
edges_other = edges[num_edges_graph:]
# split recent edges further to train and test sets
edges_train, edges_test = train_test_split(edges_other, test_size=test_subset)
print(
f"Number of edges in graph: {len(edges_graph)}\n"
f"Number of edges in training set: {len(edges_train)}\n"
f"Number of edges in test set: {len(edges_test)}"
)
Number of edges in graph: 37929
Number of edges in training set: 9482
Number of edges in test set: 3161
Create a StellarGraph¶
Now we can use the edges we’ve reserved for the graph to create an instance of the StellarGraph class
[6]:
graph = StellarGraph(
nodes=pd.DataFrame(index=full_graph.nodes()),
edges=edges_graph,
edge_weight_column="time",
)
Create link examples for training and testing¶
The edges that we’ve reserved for the train/test sets become examples of positive links.
We also need to randomly generate some examples of negative links in order to train our classifier.
[7]:
def positive_and_negative_links(g, edges):
pos = list(edges[["source", "target"]].itertuples(index=False))
neg = sample_negative_examples(g, pos)
return pos, neg
def sample_negative_examples(g, positive_examples):
positive_set = set(positive_examples)
def valid_neg_edge(src, tgt):
return (
# no self-loops
src != tgt
and
# neither direction of the edge should be a positive one
(src, tgt) not in positive_set
and (tgt, src) not in positive_set
)
possible_neg_edges = [
(src, tgt) for src in g.nodes() for tgt in g.nodes() if valid_neg_edge(src, tgt)
]
return random.sample(possible_neg_edges, k=len(positive_examples))
pos, neg = positive_and_negative_links(graph, edges_train)
pos_test, neg_test = positive_and_negative_links(graph, edges_test)
It’s good to verify that the data structures we’ve created so far from the raw data look reasonable.
StellarGraph.info is a useful method for inspecting the graph we’ve created, and we can also check that the number of link examples correspond to the train/test subset values we defined earlier.
And we can also check that the number of link examples correspond to the train/test subset values we defined earlier.
[8]:
print(
f"{graph.info()}\n"
f"Training examples: {len(pos)} positive links, {len(neg)} negative links\n"
f"Test examples: {len(pos_test)} positive links, {len(neg_test)} negative links"
)
StellarGraph: Undirected multigraph
Nodes: 151, Edges: 37929
Node types:
default: [151]
Features: none
Edge types: default-default->default
Edge types:
default-default->default: [37929]
Training examples: 9482 positive links, 9482 negative links
Test examples: 3161 positive links, 3161 negative links
Running random walks¶
Define the random walk parameters we’d like to use: * num_walks_per_node - Number of random walks to perform per starting node. * walk_length - Length of each random walk. For temporal walks, this is the maximum length of a walk, since walks may end up being shorter when there are not enough time respecting edges to traverse. * context_window_size - Size of the context window used to train the Word2Vec model.
[9]:
num_walks_per_node = 10
walk_length = 80
context_window_size = 10
We try to keep the setup comparable between the use of temporal and biased (static) random walks. For temporal walks, the input parameter is defined in terms of the total number of context windows you are interested in obtaining, which differs from the traditional approach of specifying the number of walks to run per node in the graph. We calculate the number of context windows we need in terms of the traditional parameters as:
[10]:
num_cw = len(graph.nodes()) * num_walks_per_node * (walk_length - context_window_size + 1)
We’re now ready to do the walks
[11]:
from stellargraph.data import TemporalRandomWalk
temporal_rw = TemporalRandomWalk(graph)
temporal_walks = temporal_rw.run(
num_cw=num_cw,
cw_size=context_window_size,
max_walk_length=walk_length,
walk_bias="exponential",
)
print("Number of temporal random walks: {}".format(len(temporal_walks)))
Number of temporal random walks: 1827
[12]:
from stellargraph.data import BiasedRandomWalk
static_rw = BiasedRandomWalk(graph)
static_walks = static_rw.run(
nodes=graph.nodes(), n=num_walks_per_node, length=walk_length
)
print("Number of static random walks: {}".format(len(static_walks)))
Number of static random walks: 1510
Using the random walks obtained, we can train our Word2Vec models to generate node embeddings
[13]:
from gensim.models import Word2Vec
embedding_size = 128
temporal_model = Word2Vec(
temporal_walks,
size=embedding_size,
window=context_window_size,
min_count=0,
sg=1,
workers=2,
iter=1,
)
static_model = Word2Vec(
static_walks,
size=embedding_size,
window=context_window_size,
min_count=0,
sg=1,
workers=2,
iter=1,
)
For convenience, we can use the trained Word2Vec models to define helper functions that transform a node ID into a node embedding.
NOTE: Temporal walks may not generate an embedding for every node in the graph; if there’s no temporal walks that involve a particular node or they are all too short, the node won’t appear in any context window. We handle this by using zeros as embeddings for such nodes to indicate that they are uninformative.
[14]:
unseen_node_embedding = np.zeros(embedding_size)
def temporal_embedding(u):
try:
return temporal_model.wv[u]
except KeyError:
return unseen_node_embedding
def static_embedding(u):
return static_model.wv[u]
Node Embedding Visualisation¶
For visualisation of embeddings, we’ll first define a helper function that we can also use later to show the TSNE visualisation.
[15]:
def plot_tsne(title, x, y=None):
tsne = TSNE(n_components=2)
x_t = tsne.fit_transform(x)
plt.figure(figsize=(7, 7))
plt.title(title)
alpha = 0.7 if y is None else 0.5
scatter = plt.scatter(x_t[:, 0], x_t[:, 1], c=y, cmap="jet", alpha=alpha)
if y is not None:
plt.legend(*scatter.legend_elements(), loc="lower left", title="Classes")
We can visualise the node embeddings to take a glance at how the temporal walks have resulted in groups of nodes being clustered together
[16]:
temporal_node_embeddings = temporal_model.wv.vectors
static_node_embeddings = static_model.wv.vectors
plot_tsne("TSNE visualisation of temporal node embeddings", temporal_node_embeddings)
plot_tsne("TSNE visualisation of static node embeddings", static_node_embeddings)
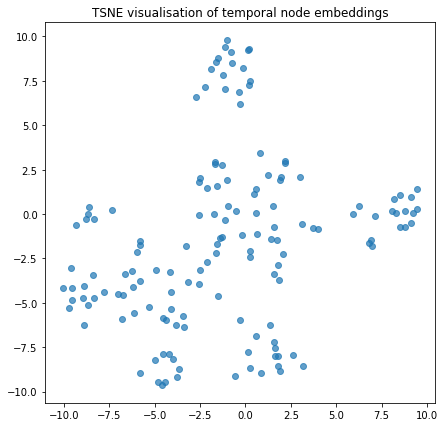
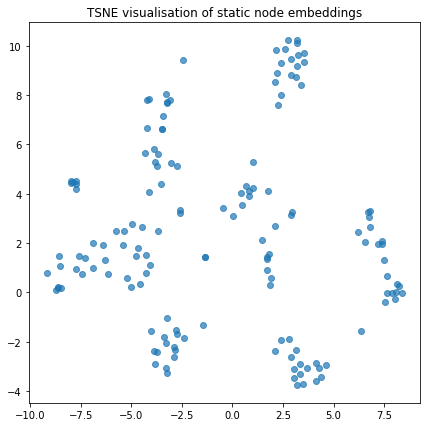
Link Prediction using Node Embeddings¶
The node embeddings we’ve generated can now be used as input for a link prediction task. The reported AUC scores from the reference paper for this dataset are:
- Node2Vec: 0.759
- CTDNE: 0.777
It turns out both the Node2Vec and CTDNE in this notebook perform much better than the paper. We may not have exactly reproduced the conditions under which the paper was testing.
Below are a set of helper functions we can use to train and evaluate a link prediction classifier. The rest of the notebook will use the binary operator defined in the cell below.
Other commonly used binary operators are hadamard, average, and L1 operators. Alternatively, other user defined function taking two node embeddings to produce a link embedding could be used, but may affect convergence of the classifier model.
[17]:
def operator_l2(u, v):
return (u - v) ** 2
binary_operator = operator_l2
[18]:
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegressionCV
from sklearn.metrics import roc_auc_score
from sklearn.preprocessing import StandardScaler
def link_examples_to_features(link_examples, transform_node):
op_func = (
operator_func[binary_operator]
if isinstance(binary_operator, str)
else binary_operator
)
return [
op_func(transform_node(src), transform_node(dst)) for src, dst in link_examples
]
def link_prediction_classifier(max_iter=2000):
lr_clf = LogisticRegressionCV(Cs=10, cv=10, scoring="roc_auc", max_iter=max_iter)
return Pipeline(steps=[("sc", StandardScaler()), ("clf", lr_clf)])
def evaluate_roc_auc(clf, link_features, link_labels):
predicted = clf.predict_proba(link_features)
# check which class corresponds to positive links
positive_column = list(clf.classes_).index(1)
return roc_auc_score(link_labels, predicted[:, positive_column])
We’ll create some positive and negative examples to train our classifier on. The negative examples can be randomly generated from the available nodes in the graph.
[19]:
def labelled_links(positive_examples, negative_examples):
return (
positive_examples + negative_examples,
np.repeat([1, 0], [len(positive_examples), len(negative_examples)]),
)
link_examples, link_labels = labelled_links(pos, neg)
link_examples_test, link_labels_test = labelled_links(pos_test, neg_test)
Link prediction classifier using temporal embeddings¶
[20]:
temporal_clf = link_prediction_classifier()
temporal_link_features = link_examples_to_features(link_examples, temporal_embedding)
temporal_link_features_test = link_examples_to_features(
link_examples_test, temporal_embedding
)
temporal_clf.fit(temporal_link_features, link_labels)
temporal_score = evaluate_roc_auc(
temporal_clf, temporal_link_features_test, link_labels_test
)
print(f"Score (ROC AUC): {temporal_score:.2f}")
Score (ROC AUC): 0.96
Link prediction classifier using static embeddings¶
[21]:
static_clf = link_prediction_classifier()
static_link_features = link_examples_to_features(link_examples, static_embedding)
static_link_features_test = link_examples_to_features(
link_examples_test, static_embedding
)
static_clf.fit(static_link_features, link_labels)
static_score = evaluate_roc_auc(static_clf, static_link_features_test, link_labels_test)
print(f"Score (ROC AUC): {static_score:.2f}")
Score (ROC AUC): 0.96
Link Embedding Visualisation¶
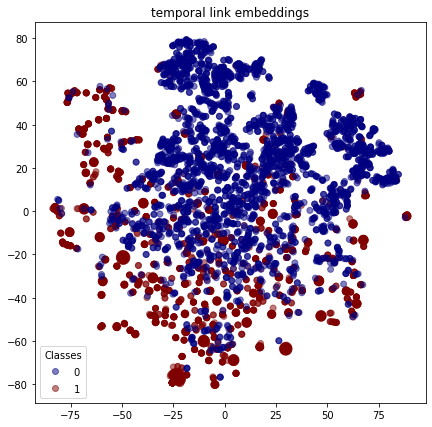
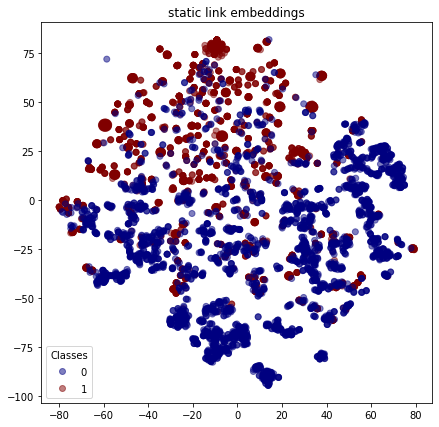
As with the nodes, we can visualise the embeddings for each link to see how the positive links (with class 1 ) are reasonably well clustered and similarly for the false links (with class 0 ).
[22]:
plot_tsne("temporal link embeddings", temporal_link_features_test, link_labels_test)
plot_tsne("static link embeddings", static_link_features_test, link_labels_test)
Run the master version of this notebook: |