ComplEx on WN18 and FB15K¶
This notebook reproduces the experiments done in the paper that introduced the ComplEx algorith: Complex Embeddings for Simple Link Prediction, Théo Trouillon, Johannes Welbl, Sebastian Riedel, Éric Gaussier and Guillaume Bouchard, ICML 2016. http://jmlr.org/proceedings/papers/v48/trouillon16.pdf
In table 2, the paper reports five metrics measured on the WN18 and FB15K datasets: “raw” MRR (mean reciprocal rank), “filtered” MRR and filtered Hits at {1, 3, 10}. This notebook measures all of these, as well as raw Hits at {1, 3, 10}.
Run the master version of this notebook: |
[1]:
# install StellarGraph if running on Google Colab
import sys
if 'google.colab' in sys.modules:
%pip install -q stellargraph[demos]==1.0.0rc1
[2]:
# verify that we're using the correct version of StellarGraph for this notebook
import stellargraph as sg
try:
sg.utils.validate_notebook_version("1.0.0rc1")
except AttributeError:
raise ValueError(
f"This notebook requires StellarGraph version 1.0.0rc1, but a different version {sg.__version__} is installed. Please see <https://github.com/stellargraph/stellargraph/issues/1172>."
) from None
[3]:
from stellargraph import datasets, utils
from tensorflow.keras import callbacks, optimizers, losses, metrics, regularizers, Model
import numpy as np
import pandas as pd
from stellargraph.mapper import KGTripleGenerator
from stellargraph.layer import ComplEx
from IPython.display import HTML
Initialisation¶
We need to set up our model parameters, like the number of epochs to train for, and the dimension of the embedding vectors we compute for each node and for each edge type.
The evaluation is performed in three steps:
- Load the data
- Train a model
- Evaluate the model
The paper says that it used: - the AdaGrad optimiser for 1000 epochs with an early stopping criterion evaluated every 50 epochs, but we’ve found using the Adam optimiser allows for much fewer epochs - an embedding dimension of 150 or 200, since they had close results - 10 negative samples (corrupted edges) per positive edge, which gives noticably improved performance on FB15k compared to using 1, and but not for WN18 (the paper evaluated 1, 2, 5 and 10 negative samples)
[4]:
epochs = 50
embedding_dimension = 200
negative_samples = 10
WN18¶
The paper uses the WN18 and FB15k datasets for validation. These datasets are not good for evaluating algorithms because they contain “inverse relations”, where (s, r1, o) implies (o, r2, s) for a pair of relation types r1 and r2 (for instance, _hyponym (“is more specific than”) and _hypernym (“is more general than”) in WN18), however, they work fine to demonstrate StellarGraph’s functionality, and are appropriate to compare against the published results.
Load the data¶
The dataset comes with a defined train, test and validation split, each consisting of subject, relation, object triples. We can load a StellarGraph object with all of the triples, as well as the individual splits as Pandas DataFrames, using the load method of the WN18 dataset.
[5]:
wn18 = datasets.WN18()
display(HTML(wn18.description))
wn18_graph, wn18_train, wn18_test, wn18_valid = wn18.load()
[6]:
print(wn18_graph.info())
StellarDiGraph: Directed multigraph
Nodes: 40943, Edges: 151442
Node types:
default: [40943]
Features: none
Edge types: default-_also_see->default, default-_derivationally_related_form->default, default-_has_part->default, default-_hypernym->default, default-_hyponym->default, ... (13 more)
Edge types:
default-_hyponym->default: [37221]
default-_hypernym->default: [37221]
default-_derivationally_related_form->default: [31867]
default-_member_meronym->default: [7928]
default-_member_holonym->default: [7928]
default-_part_of->default: [5148]
default-_has_part->default: [5142]
default-_member_of_domain_topic->default: [3341]
default-_synset_domain_topic_of->default: [3335]
default-_instance_hyponym->default: [3150]
default-_instance_hypernym->default: [3150]
default-_also_see->default: [1396]
default-_verb_group->default: [1220]
default-_member_of_domain_region->default: [983]
default-_synset_domain_region_of->default: [982]
default-_member_of_domain_usage->default: [675]
default-_synset_domain_usage_of->default: [669]
default-_similar_to->default: [86]
Train a model¶
The ComplEx algorithm consists of some embedding layers and a scoring layer, but the ComplEx object means these details are invisible to us. The ComplEx model consumes “knowledge-graph triples”, which can be produced in the appropriate format using KGTripleGenerator.
[7]:
wn18_gen = KGTripleGenerator(
wn18_graph, batch_size=len(wn18_train) // 100 # ~100 batches per epoch
)
wn18_complex = ComplEx(
wn18_gen,
embedding_dimension=embedding_dimension,
embeddings_regularizer=regularizers.l2(1e-7),
)
wn18_inp, wn18_out = wn18_complex.in_out_tensors()
wn18_model = Model(inputs=wn18_inp, outputs=wn18_out)
wn18_model.compile(
optimizer=optimizers.Adam(lr=0.001),
loss=losses.BinaryCrossentropy(from_logits=True),
metrics=[metrics.BinaryAccuracy(threshold=0.0)],
)
Inputs for training are produced by calling the KGTripleGenerator.flow method, this takes a dataframe with source, label and target columns, where each row is a true edge in the knowledge graph. The negative_samples parameter controls how many random edges are created for each positive edge to use as negative examples for training.
[8]:
wn18_train_gen = wn18_gen.flow(
wn18_train, negative_samples=negative_samples, shuffle=True
)
wn18_valid_gen = wn18_gen.flow(wn18_valid, negative_samples=negative_samples)
[9]:
wn18_es = callbacks.EarlyStopping(monitor="val_loss", patience=10)
wn18_history = wn18_model.fit(
wn18_train_gen, validation_data=wn18_valid_gen, epochs=epochs, callbacks=[wn18_es]
)
Train for 101 steps, validate for 4 steps
Epoch 1/50
101/101 [==============================] - 24s 240ms/step - loss: 0.6971 - binary_accuracy: 0.5005 - val_loss: 0.6970 - val_binary_accuracy: 0.5013
Epoch 2/50
101/101 [==============================] - 23s 230ms/step - loss: 0.6967 - binary_accuracy: 0.5067 - val_loss: 0.6966 - val_binary_accuracy: 0.4989
Epoch 3/50
101/101 [==============================] - 23s 230ms/step - loss: 0.6963 - binary_accuracy: 0.5180 - val_loss: 0.6961 - val_binary_accuracy: 0.5077
Epoch 4/50
101/101 [==============================] - 23s 231ms/step - loss: 0.6958 - binary_accuracy: 0.5308 - val_loss: 0.6957 - val_binary_accuracy: 0.5162
Epoch 5/50
101/101 [==============================] - 24s 242ms/step - loss: 0.6953 - binary_accuracy: 0.5430 - val_loss: 0.6953 - val_binary_accuracy: 0.5318
Epoch 6/50
101/101 [==============================] - 24s 236ms/step - loss: 0.6942 - binary_accuracy: 0.5969 - val_loss: 0.6930 - val_binary_accuracy: 0.7030
Epoch 7/50
101/101 [==============================] - 24s 237ms/step - loss: 0.6784 - binary_accuracy: 0.8850 - val_loss: 0.6488 - val_binary_accuracy: 0.9090
Epoch 8/50
101/101 [==============================] - 24s 242ms/step - loss: 0.5640 - binary_accuracy: 0.9092 - val_loss: 0.4654 - val_binary_accuracy: 0.9091
Epoch 9/50
101/101 [==============================] - 24s 239ms/step - loss: 0.3702 - binary_accuracy: 0.9107 - val_loss: 0.3183 - val_binary_accuracy: 0.9108
Epoch 10/50
101/101 [==============================] - 24s 241ms/step - loss: 0.2636 - binary_accuracy: 0.9190 - val_loss: 0.2561 - val_binary_accuracy: 0.9176
Epoch 11/50
101/101 [==============================] - 24s 237ms/step - loss: 0.1915 - binary_accuracy: 0.9382 - val_loss: 0.2023 - val_binary_accuracy: 0.9316
Epoch 12/50
101/101 [==============================] - 24s 236ms/step - loss: 0.1316 - binary_accuracy: 0.9671 - val_loss: 0.1555 - val_binary_accuracy: 0.9520
Epoch 13/50
101/101 [==============================] - 24s 234ms/step - loss: 0.0928 - binary_accuracy: 0.9854 - val_loss: 0.1226 - val_binary_accuracy: 0.9695
Epoch 14/50
101/101 [==============================] - 24s 235ms/step - loss: 0.0711 - binary_accuracy: 0.9939 - val_loss: 0.1019 - val_binary_accuracy: 0.9817
Epoch 15/50
101/101 [==============================] - 24s 235ms/step - loss: 0.0597 - binary_accuracy: 0.9971 - val_loss: 0.0897 - val_binary_accuracy: 0.9882
Epoch 16/50
101/101 [==============================] - 23s 229ms/step - loss: 0.0535 - binary_accuracy: 0.9982 - val_loss: 0.0825 - val_binary_accuracy: 0.9917
Epoch 17/50
101/101 [==============================] - 24s 236ms/step - loss: 0.0496 - binary_accuracy: 0.9988 - val_loss: 0.0784 - val_binary_accuracy: 0.9927
Epoch 18/50
101/101 [==============================] - 24s 240ms/step - loss: 0.0472 - binary_accuracy: 0.9991 - val_loss: 0.0754 - val_binary_accuracy: 0.9936
Epoch 19/50
101/101 [==============================] - 24s 236ms/step - loss: 0.0454 - binary_accuracy: 0.9993 - val_loss: 0.0741 - val_binary_accuracy: 0.9936
Epoch 20/50
101/101 [==============================] - 24s 235ms/step - loss: 0.0444 - binary_accuracy: 0.9993 - val_loss: 0.0728 - val_binary_accuracy: 0.9938
Epoch 21/50
101/101 [==============================] - 24s 235ms/step - loss: 0.0434 - binary_accuracy: 0.9994 - val_loss: 0.0717 - val_binary_accuracy: 0.9939
Epoch 22/50
101/101 [==============================] - 24s 237ms/step - loss: 0.0427 - binary_accuracy: 0.9994 - val_loss: 0.0702 - val_binary_accuracy: 0.9941
Epoch 23/50
101/101 [==============================] - 24s 238ms/step - loss: 0.0420 - binary_accuracy: 0.9994 - val_loss: 0.0697 - val_binary_accuracy: 0.9940
Epoch 24/50
101/101 [==============================] - 24s 237ms/step - loss: 0.0414 - binary_accuracy: 0.9994 - val_loss: 0.0690 - val_binary_accuracy: 0.9941
Epoch 25/50
101/101 [==============================] - 24s 237ms/step - loss: 0.0408 - binary_accuracy: 0.9994 - val_loss: 0.0693 - val_binary_accuracy: 0.9938
Epoch 26/50
101/101 [==============================] - 24s 238ms/step - loss: 0.0404 - binary_accuracy: 0.9994 - val_loss: 0.0684 - val_binary_accuracy: 0.9938
Epoch 27/50
101/101 [==============================] - 24s 234ms/step - loss: 0.0398 - binary_accuracy: 0.9995 - val_loss: 0.0680 - val_binary_accuracy: 0.9938
Epoch 28/50
101/101 [==============================] - 24s 237ms/step - loss: 0.0394 - binary_accuracy: 0.9994 - val_loss: 0.0667 - val_binary_accuracy: 0.9941
Epoch 29/50
101/101 [==============================] - 24s 236ms/step - loss: 0.0390 - binary_accuracy: 0.9994 - val_loss: 0.0666 - val_binary_accuracy: 0.9940
Epoch 30/50
101/101 [==============================] - 24s 239ms/step - loss: 0.0385 - binary_accuracy: 0.9994 - val_loss: 0.0661 - val_binary_accuracy: 0.9940
Epoch 31/50
101/101 [==============================] - 24s 238ms/step - loss: 0.0381 - binary_accuracy: 0.9994 - val_loss: 0.0659 - val_binary_accuracy: 0.9941
Epoch 32/50
101/101 [==============================] - 24s 235ms/step - loss: 0.0377 - binary_accuracy: 0.9994 - val_loss: 0.0657 - val_binary_accuracy: 0.9939
Epoch 33/50
101/101 [==============================] - 24s 235ms/step - loss: 0.0373 - binary_accuracy: 0.9994 - val_loss: 0.0642 - val_binary_accuracy: 0.9941
Epoch 34/50
101/101 [==============================] - 24s 238ms/step - loss: 0.0369 - binary_accuracy: 0.9994 - val_loss: 0.0640 - val_binary_accuracy: 0.9940
Epoch 35/50
101/101 [==============================] - 24s 234ms/step - loss: 0.0365 - binary_accuracy: 0.9994 - val_loss: 0.0638 - val_binary_accuracy: 0.9940
Epoch 36/50
101/101 [==============================] - 24s 239ms/step - loss: 0.0362 - binary_accuracy: 0.9994 - val_loss: 0.0639 - val_binary_accuracy: 0.9938
Epoch 37/50
101/101 [==============================] - 25s 246ms/step - loss: 0.0359 - binary_accuracy: 0.9994 - val_loss: 0.0629 - val_binary_accuracy: 0.9941
Epoch 38/50
101/101 [==============================] - 24s 237ms/step - loss: 0.0355 - binary_accuracy: 0.9994 - val_loss: 0.0622 - val_binary_accuracy: 0.9940
Epoch 39/50
101/101 [==============================] - 24s 233ms/step - loss: 0.0351 - binary_accuracy: 0.9994 - val_loss: 0.0624 - val_binary_accuracy: 0.9939
Epoch 40/50
101/101 [==============================] - 24s 234ms/step - loss: 0.0347 - binary_accuracy: 0.9994 - val_loss: 0.0610 - val_binary_accuracy: 0.9941
Epoch 41/50
101/101 [==============================] - 23s 231ms/step - loss: 0.0344 - binary_accuracy: 0.9994 - val_loss: 0.0617 - val_binary_accuracy: 0.9941
Epoch 42/50
101/101 [==============================] - 23s 229ms/step - loss: 0.0340 - binary_accuracy: 0.9994 - val_loss: 0.0608 - val_binary_accuracy: 0.9941
Epoch 43/50
101/101 [==============================] - 23s 232ms/step - loss: 0.0335 - binary_accuracy: 0.9994 - val_loss: 0.0599 - val_binary_accuracy: 0.9943
Epoch 44/50
101/101 [==============================] - 23s 231ms/step - loss: 0.0331 - binary_accuracy: 0.9995 - val_loss: 0.0610 - val_binary_accuracy: 0.9938
Epoch 45/50
101/101 [==============================] - 23s 232ms/step - loss: 0.0329 - binary_accuracy: 0.9994 - val_loss: 0.0601 - val_binary_accuracy: 0.9940
Epoch 46/50
101/101 [==============================] - 23s 232ms/step - loss: 0.0326 - binary_accuracy: 0.9994 - val_loss: 0.0596 - val_binary_accuracy: 0.9940
Epoch 47/50
101/101 [==============================] - 23s 230ms/step - loss: 0.0324 - binary_accuracy: 0.9994 - val_loss: 0.0596 - val_binary_accuracy: 0.9939
Epoch 48/50
101/101 [==============================] - 24s 238ms/step - loss: 0.0320 - binary_accuracy: 0.9994 - val_loss: 0.0597 - val_binary_accuracy: 0.9939
Epoch 49/50
101/101 [==============================] - 24s 241ms/step - loss: 0.0317 - binary_accuracy: 0.9994 - val_loss: 0.0595 - val_binary_accuracy: 0.9938
Epoch 50/50
101/101 [==============================] - 24s 241ms/step - loss: 0.0315 - binary_accuracy: 0.9994 - val_loss: 0.0580 - val_binary_accuracy: 0.9942
[10]:
utils.plot_history(wn18_history)
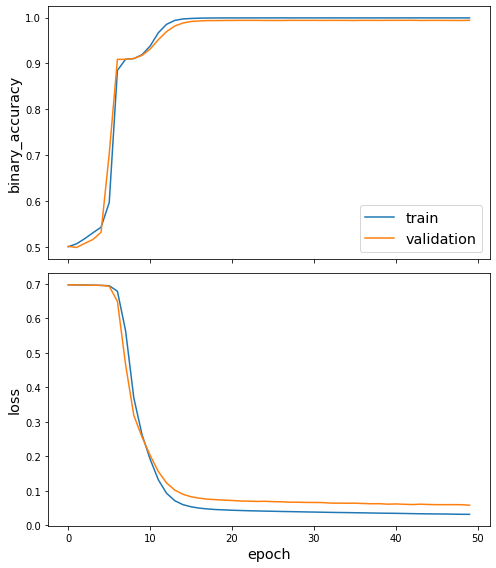
Evaluate the model¶
We’ve now trained a model, so we can apply the evaluation procedure from the paper to it. This is done by taking each test edge E = (s, r, o), and scoring it against all mutations (s, r, n) and (n, r, o) for every node n in the graph, that is, doing a prediction for every one of these edges similar to E. The “raw” rank is the number of mutated edges that have a higher predicted score than the true E.
[11]:
wn18_raw_ranks, wn18_filtered_ranks = wn18_complex.rank_edges_against_all_nodes(
wn18_gen.flow(wn18_test), wn18_graph
)
[12]:
# helper function to compute metrics from a dictionary of name -> array of ranks
def results_as_dataframe(name_to_results):
return pd.DataFrame(
name_to_results.values(),
columns=["mrr", "hits at 1", "hits at 3", "hits at 10"],
index=name_to_results.keys(),
)
def summarise(name_to_ranks):
return results_as_dataframe(
{
name: (
np.mean(1 / ranks),
np.mean(ranks <= 1),
np.mean(ranks < 3),
np.mean(ranks <= 10),
)
for name, ranks in name_to_ranks.items()
}
)
[13]:
summarise({"raw": wn18_raw_ranks, "filtered": wn18_filtered_ranks})
[13]:
| mrr | hits at 1 | hits at 3 | hits at 10 | |
|---|---|---|---|---|
| raw | 0.598731 | 0.4814 | 0.6065 | 0.8192 |
| filtered | 0.940128 | 0.9299 | 0.9451 | 0.9546 |
For comparison, Table 2 in the paper gives the following results for WN18 (NaN denotes values the paper does not include). All of the numbers are similar:
[14]:
results_as_dataframe(
{"raw": (0.587, None, None, None), "filtered": (0.941, 0.936, 0.945, 0.947)}
)
[14]:
| mrr | hits at 1 | hits at 3 | hits at 10 | |
|---|---|---|---|---|
| raw | 0.587 | NaN | NaN | NaN |
| filtered | 0.941 | 0.936 | 0.945 | 0.947 |
FB15k¶
Now that we know the process, we can apply the model on the FB15k dataset in the same way.
Loading the data¶
[15]:
fb15k = datasets.FB15k()
display(HTML(fb15k.description))
fb15k_graph, fb15k_train, fb15k_test, fb15k_valid = fb15k.load()
[16]:
print(fb15k_graph.info())
StellarDiGraph: Directed multigraph
Nodes: 14951, Edges: 592213
Node types:
default: [14951]
Features: none
Edge types: default-/american_football/football_coach/coaching_history./american_football/football_historical_coach_position/position->default, default-/american_football/football_coach/coaching_history./american_football/football_historical_coach_position/team->default, default-/american_football/football_coach_position/coaches_holding_this_position./american_football/football_historical_coach_position/coach->default, default-/american_football/football_coach_position/coaches_holding_this_position./american_football/football_historical_coach_position/team->default, default-/american_football/football_player/current_team./american_football/football_roster_position/position->default, ... (1340 more)
Edge types:
default-/award/award_nominee/award_nominations./award/award_nomination/award_nominee->default: [19764]
default-/film/film/release_date_s./film/film_regional_release_date/film_release_region->default: [15837]
default-/award/award_nominee/award_nominations./award/award_nomination/award->default: [14921]
default-/award/award_category/nominees./award/award_nomination/award_nominee->default: [14921]
default-/people/profession/people_with_this_profession->default: [14220]
default-/people/person/profession->default: [14220]
default-/film/film/starring./film/performance/actor->default: [11638]
default-/film/actor/film./film/performance/film->default: [11638]
default-/award/award_nominated_work/award_nominations./award/award_nomination/award->default: [11594]
default-/award/award_category/nominees./award/award_nomination/nominated_for->default: [11594]
default-/award/award_winner/awards_won./award/award_honor/award_winner->default: [10378]
default-/film/film_genre/films_in_this_genre->default: [8946]
default-/film/film/genre->default: [8946]
default-/award/award_nominee/award_nominations./award/award_nomination/nominated_for->default: [7632]
default-/award/award_nominated_work/award_nominations./award/award_nomination/award_nominee->default: [7632]
default-/film/film_job/films_with_this_crew_job./film/film_crew_gig/film->default: [7400]
default-/film/film/other_crew./film/film_crew_gig/film_crew_role->default: [7400]
default-/common/topic/webpage./common/webpage/category->default: [7232]
default-/common/annotation_category/annotations./common/webpage/topic->default: [7232]
default-/music/genre/artists->default: [7229]
... (1325 more)
Train a model¶
[17]:
fb15k_gen = KGTripleGenerator(
fb15k_graph, batch_size=len(fb15k_train) // 100 # ~100 batches per epoch
)
fb15k_complex = ComplEx(
fb15k_gen,
embedding_dimension=embedding_dimension,
embeddings_regularizer=regularizers.l2(1e-8),
)
fb15k_inp, fb15k_out = fb15k_complex.in_out_tensors()
fb15k_model = Model(inputs=fb15k_inp, outputs=fb15k_out)
fb15k_model.compile(
optimizer=optimizers.Adam(lr=0.001),
loss=losses.BinaryCrossentropy(from_logits=True),
metrics=[metrics.BinaryAccuracy(threshold=0.0)],
)
[18]:
fb15k_train_gen = fb15k_gen.flow(
fb15k_train, negative_samples=negative_samples, shuffle=True
)
fb15k_valid_gen = fb15k_gen.flow(fb15k_valid, negative_samples=negative_samples)
[19]:
fb15k_es = callbacks.EarlyStopping(monitor="val_loss", patience=10)
fb15k_history = fb15k_model.fit(
fb15k_train_gen, validation_data=fb15k_valid_gen, epochs=epochs, callbacks=[fb15k_es]
)
Train for 101 steps, validate for 11 steps
Epoch 1/50
101/101 [==============================] - 41s 401ms/step - loss: 0.6933 - binary_accuracy: 0.5003 - val_loss: 0.6933 - val_binary_accuracy: 0.5016
Epoch 2/50
101/101 [==============================] - 40s 394ms/step - loss: 0.6933 - binary_accuracy: 0.5035 - val_loss: 0.6933 - val_binary_accuracy: 0.5024
Epoch 3/50
101/101 [==============================] - 41s 402ms/step - loss: 0.6932 - binary_accuracy: 0.5107 - val_loss: 0.6932 - val_binary_accuracy: 0.5129
Epoch 4/50
101/101 [==============================] - 41s 408ms/step - loss: 0.6927 - binary_accuracy: 0.5552 - val_loss: 0.6911 - val_binary_accuracy: 0.6468
Epoch 5/50
101/101 [==============================] - 42s 416ms/step - loss: 0.6597 - binary_accuracy: 0.8393 - val_loss: 0.5786 - val_binary_accuracy: 0.9068
Epoch 6/50
101/101 [==============================] - 42s 417ms/step - loss: 0.4349 - binary_accuracy: 0.9086 - val_loss: 0.3232 - val_binary_accuracy: 0.9097
Epoch 7/50
101/101 [==============================] - 43s 424ms/step - loss: 0.2778 - binary_accuracy: 0.9140 - val_loss: 0.2465 - val_binary_accuracy: 0.9178
Epoch 8/50
101/101 [==============================] - 43s 429ms/step - loss: 0.2200 - binary_accuracy: 0.9232 - val_loss: 0.2014 - val_binary_accuracy: 0.9265
Epoch 9/50
101/101 [==============================] - 43s 423ms/step - loss: 0.1778 - binary_accuracy: 0.9333 - val_loss: 0.1643 - val_binary_accuracy: 0.9367
Epoch 10/50
101/101 [==============================] - 42s 411ms/step - loss: 0.1452 - binary_accuracy: 0.9443 - val_loss: 0.1389 - val_binary_accuracy: 0.9453
Epoch 11/50
101/101 [==============================] - 42s 412ms/step - loss: 0.1220 - binary_accuracy: 0.9530 - val_loss: 0.1215 - val_binary_accuracy: 0.9515
Epoch 12/50
101/101 [==============================] - 41s 407ms/step - loss: 0.1051 - binary_accuracy: 0.9599 - val_loss: 0.1091 - val_binary_accuracy: 0.9559
Epoch 13/50
101/101 [==============================] - 41s 405ms/step - loss: 0.0925 - binary_accuracy: 0.9653 - val_loss: 0.0995 - val_binary_accuracy: 0.9598
Epoch 14/50
101/101 [==============================] - 41s 404ms/step - loss: 0.0823 - binary_accuracy: 0.9699 - val_loss: 0.0922 - val_binary_accuracy: 0.9628
Epoch 15/50
101/101 [==============================] - 41s 408ms/step - loss: 0.0741 - binary_accuracy: 0.9736 - val_loss: 0.0862 - val_binary_accuracy: 0.9657
Epoch 16/50
101/101 [==============================] - 41s 405ms/step - loss: 0.0676 - binary_accuracy: 0.9765 - val_loss: 0.0820 - val_binary_accuracy: 0.9674
Epoch 17/50
101/101 [==============================] - 41s 408ms/step - loss: 0.0622 - binary_accuracy: 0.9788 - val_loss: 0.0789 - val_binary_accuracy: 0.9687
Epoch 18/50
101/101 [==============================] - 41s 406ms/step - loss: 0.0579 - binary_accuracy: 0.9805 - val_loss: 0.0755 - val_binary_accuracy: 0.9704
Epoch 19/50
101/101 [==============================] - 41s 407ms/step - loss: 0.0542 - binary_accuracy: 0.9818 - val_loss: 0.0736 - val_binary_accuracy: 0.9717
Epoch 20/50
101/101 [==============================] - 41s 410ms/step - loss: 0.0513 - binary_accuracy: 0.9829 - val_loss: 0.0718 - val_binary_accuracy: 0.9728
Epoch 21/50
101/101 [==============================] - 41s 411ms/step - loss: 0.0490 - binary_accuracy: 0.9837 - val_loss: 0.0709 - val_binary_accuracy: 0.9732
Epoch 22/50
101/101 [==============================] - 42s 413ms/step - loss: 0.0468 - binary_accuracy: 0.9844 - val_loss: 0.0697 - val_binary_accuracy: 0.9739
Epoch 23/50
101/101 [==============================] - 42s 414ms/step - loss: 0.0451 - binary_accuracy: 0.9850 - val_loss: 0.0694 - val_binary_accuracy: 0.9743
Epoch 24/50
101/101 [==============================] - 42s 412ms/step - loss: 0.0435 - binary_accuracy: 0.9855 - val_loss: 0.0693 - val_binary_accuracy: 0.9744
Epoch 25/50
101/101 [==============================] - 42s 417ms/step - loss: 0.0425 - binary_accuracy: 0.9859 - val_loss: 0.0686 - val_binary_accuracy: 0.9748
Epoch 26/50
101/101 [==============================] - 42s 414ms/step - loss: 0.0412 - binary_accuracy: 0.9863 - val_loss: 0.0683 - val_binary_accuracy: 0.9750
Epoch 27/50
101/101 [==============================] - 42s 413ms/step - loss: 0.0403 - binary_accuracy: 0.9866 - val_loss: 0.0689 - val_binary_accuracy: 0.9752
Epoch 28/50
101/101 [==============================] - 41s 411ms/step - loss: 0.0394 - binary_accuracy: 0.9868 - val_loss: 0.0681 - val_binary_accuracy: 0.9754
Epoch 29/50
101/101 [==============================] - 42s 416ms/step - loss: 0.0385 - binary_accuracy: 0.9871 - val_loss: 0.0690 - val_binary_accuracy: 0.9752
Epoch 30/50
101/101 [==============================] - 42s 415ms/step - loss: 0.0378 - binary_accuracy: 0.9874 - val_loss: 0.0694 - val_binary_accuracy: 0.9757
Epoch 31/50
101/101 [==============================] - 42s 414ms/step - loss: 0.0373 - binary_accuracy: 0.9875 - val_loss: 0.0696 - val_binary_accuracy: 0.9754
Epoch 32/50
101/101 [==============================] - 42s 415ms/step - loss: 0.0367 - binary_accuracy: 0.9877 - val_loss: 0.0696 - val_binary_accuracy: 0.9756
Epoch 33/50
101/101 [==============================] - 42s 416ms/step - loss: 0.0364 - binary_accuracy: 0.9878 - val_loss: 0.0704 - val_binary_accuracy: 0.9755
Epoch 34/50
101/101 [==============================] - 42s 414ms/step - loss: 0.0359 - binary_accuracy: 0.9879 - val_loss: 0.0707 - val_binary_accuracy: 0.9755
Epoch 35/50
101/101 [==============================] - 42s 413ms/step - loss: 0.0354 - binary_accuracy: 0.9881 - val_loss: 0.0713 - val_binary_accuracy: 0.9759
Epoch 36/50
101/101 [==============================] - 42s 415ms/step - loss: 0.0350 - binary_accuracy: 0.9882 - val_loss: 0.0714 - val_binary_accuracy: 0.9756
Epoch 37/50
101/101 [==============================] - 42s 412ms/step - loss: 0.0347 - binary_accuracy: 0.9883 - val_loss: 0.0718 - val_binary_accuracy: 0.9758
Epoch 38/50
101/101 [==============================] - 42s 416ms/step - loss: 0.0343 - binary_accuracy: 0.9883 - val_loss: 0.0724 - val_binary_accuracy: 0.9754
[20]:
utils.plot_history(fb15k_history)
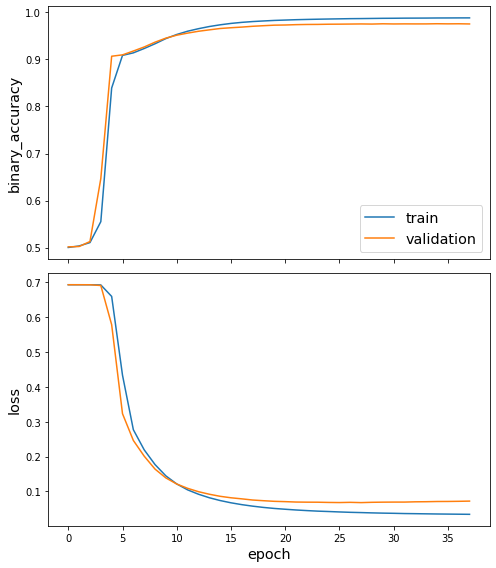
Evaluate the model¶
[21]:
fb15k_raw_ranks, fb15k_filtered_ranks = fb15k_complex.rank_edges_against_all_nodes(
fb15k_gen.flow(fb15k_test), fb15k_graph
)
[22]:
summarise({"raw": fb15k_raw_ranks, "filtered": fb15k_filtered_ranks})
[22]:
| mrr | hits at 1 | hits at 3 | hits at 10 | |
|---|---|---|---|---|
| raw | 0.257589 | 0.141330 | 0.227133 | 0.513856 |
| filtered | 0.591330 | 0.464069 | 0.613778 | 0.818049 |
For comparison, Table 2 in the paper gives the following results for FB15k:
[23]:
results_as_dataframe(
{"raw": (0.242, None, None, None), "filtered": (0.692, 0.599, 0.759, 0.850)}
)
[23]:
| mrr | hits at 1 | hits at 3 | hits at 10 | |
|---|---|---|---|---|
| raw | 0.242 | NaN | NaN | NaN |
| filtered | 0.692 | 0.599 | 0.759 | 0.85 |
Run the master version of this notebook: |