Execute this notebook:
![]()
![]() Download locally
Download locally
Node classification with Simplified Graph Convolutions (SGC)¶
This notebook demonstrates the use of StellarGraph’s GCN [2], class for training the simplified graph convolution (SGC) model in introduced in [1].
We show how to use StellarGraph to perform node attribute inference on the Cora citation network using SGC by creating a single layer GCN model with softmax activation.
SGC simplifies GCN in the following ways,
It removes the non-linearities in the graph convolutional layers.
It smooths the node input features using powers of the normalized adjacency matrix with self loops (see [2]).
It uses a single softmax layer such that GCN is simplified to logistic regression on smoothed node features.
For a graph with \(N\) nodes, \(F\)-dimensional node features and \(C\) number of classes, SGC simplifies GCN using the following logistic regression classifier with smoothed features,
\(\hat{\boldsymbol{Y}}_{SGC} = \mathtt{softmax}(\boldsymbol{S}^K \boldsymbol{X}\; \boldsymbol{\Theta})\)
where \(\hat{\boldsymbol{Y}}_{SGC} \in \mathbb{R}^{N\times C}\) are the class predictions; \(\boldsymbol{S}^K \in \mathbb{R}^{N\times N}\) is the normalised graph adjacency matrix with self loops raised to the K-th power; \(\boldsymbol{X}\in \mathbb{R}^{N\times F}\) are the node input features; and \(\boldsymbol{\Theta} \in \mathbb{R}^{F\times C}\) are the classifier’s parameters to be learned.
References
[1] Simplifying Graph Convolutional Networks. F. Wu, T. Zhang, A. H. de Souza Jr., C. Fifty, T. Yu, and K. Q. Weinberger, arXiv: 1902.07153. link
[2] Semi-Supervised Classification with Graph Convolutional Networks. T. N. Kipf and M. Welling, ICLR 2016. link
[3]:
import pandas as pd
import os
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
import pandas as pd
import numpy as np
import stellargraph as sg
from stellargraph.mapper import FullBatchNodeGenerator
from stellargraph.layer import GCN
from tensorflow.keras import layers, optimizers, losses, metrics, Model, regularizers
from sklearn import preprocessing, feature_extraction, model_selection
from stellargraph import datasets
from IPython.display import display, HTML
import matplotlib.pyplot as plt
%matplotlib inline
Loading the CORA network¶
Create graph using the Cora loader from datasets.
(See the “Loading from Pandas” demo for details on how data can be loaded.)
[4]:
dataset = datasets.Cora()
display(HTML(dataset.description))
G, node_subjects = dataset.load()
[5]:
print(G.info())
StellarGraph: Undirected multigraph
Nodes: 2708, Edges: 5429
Node types:
paper: [2708]
Edge types: paper-cites->paper
Edge types:
paper-cites->paper: [5429]
We aim to train a graph-ML model that will predict the “subject” attribute on the nodes. These subjects are one of 7 categories:
[6]:
set(node_subjects)
[6]:
{'Case_Based',
'Genetic_Algorithms',
'Neural_Networks',
'Probabilistic_Methods',
'Reinforcement_Learning',
'Rule_Learning',
'Theory'}
Splitting the data¶
For machine learning we want to take a subset of the nodes for training, and use the rest for validation and testing. We’ll use scikit-learn again to do this.
Here we’re taking 140 node labels for training, 500 for validation, and the rest for testing.
[7]:
train_subjects, test_subjects = model_selection.train_test_split(
node_subjects, train_size=140, test_size=None, stratify=node_subjects
)
val_subjects, test_subjects = model_selection.train_test_split(
test_subjects, train_size=500, test_size=None, stratify=test_subjects
)
Note using stratified sampling gives the following counts:
[8]:
from collections import Counter
Counter(train_subjects)
[8]:
Counter({'Theory': 18,
'Neural_Networks': 42,
'Genetic_Algorithms': 22,
'Probabilistic_Methods': 22,
'Case_Based': 16,
'Rule_Learning': 9,
'Reinforcement_Learning': 11})
The training set has class imbalance that might need to be compensated, e.g., via using a weighted cross-entropy loss in model training, with class weights inversely proportional to class support. However, we will ignore the class imbalance in this example, for simplicity.
Converting to numeric arrays¶
For our categorical target, we will use one-hot vectors that will be fed into a soft-max Keras layer during training. To do this conversion …
[9]:
target_encoding = preprocessing.LabelBinarizer()
train_targets = target_encoding.fit_transform(train_subjects)
val_targets = target_encoding.transform(val_subjects)
test_targets = target_encoding.transform(test_subjects)
We now do the same for the node attributes we want to use to predict the subject. These are the feature vectors that the Keras model will use as input. The CORA dataset contains attributes ‘w_x’ that correspond to words found in that publication. If a word occurs more than once in a publication the relevant attribute will be set to one, otherwise it will be zero.
Prepare node generator¶
To feed data from the graph to the Keras model we need a generator. Since SGC is a full-batch model, we use the FullBatchNodeGenerator class to feed node features and graph adjacency matrix to the model.
For SGC, we need to tell the generator to smooth the node features by some power of the normalised adjacency matrix with self loops before multiplying by the model parameters.
We achieve this by specifying model='sgc' and k=2, in this example, to use the SGC method and take the square of the adjacency matrix. For the setting k=2 we are considering a 2-hop neighbourhood that is equivalent to a 2-layer GCN. We can set k larger to consider larger node neighbourhoods but this carries an associated computational penalty.
[10]:
generator = FullBatchNodeGenerator(G, method="sgc", k=2)
Calculating 2-th power of normalized A...
For training we map only the training nodes returned from our splitter and the target values.
[11]:
train_gen = generator.flow(train_subjects.index, train_targets)
Creating the SGC model in Keras¶
Now we can specify our machine learning model, we need a few more parameters for this:
the
layer_sizesis a list of hidden feature sizes of each layer in the model. For SGC, we use a single hidden layer with output dimensionality equal to the number of classes.activationsis the activation function for the output layer. For SGC the output layer is the classification layer and for multi-class classification it should be asoftmaxactivation.Arguments such as
biasanddropoutare internal parameters of the model, execute?GCNfor details.
Note: The SGC model is a single layer GCN model with softmax activation and the full batch generator we created above that smooths the node features based on the graph structure. So, our SGC model is declared as a StellarGraph.layer.GCN model.
[12]:
sgc = GCN(
layer_sizes=[train_targets.shape[1]],
generator=generator,
bias=True,
dropout=0.5,
activations=["softmax"],
kernel_regularizer=regularizers.l2(5e-4),
)
[13]:
# Expose the input and output tensors of the SGC model for node prediction,
# via GCN.in_out_tensors() method:
x_inp, predictions = sgc.in_out_tensors()
Training the model¶
Now let’s create the actual Keras model with the input tensors x_inp and output tensors being the predictions predictions from the final dense layer
[14]:
model = Model(inputs=x_inp, outputs=predictions)
model.compile(
optimizer=optimizers.Adam(lr=0.2),
loss=losses.categorical_crossentropy,
metrics=["acc"],
)
Train the model, keeping track of its loss and accuracy on the training set, and its generalisation performance on the validation set (we need to create another generator over the validation data for this)
[15]:
val_gen = generator.flow(val_subjects.index, val_targets)
Create callbacks for early stopping (if validation accuracy stops improving) and best model checkpoint saving:
[16]:
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
if not os.path.isdir("logs"):
os.makedirs("logs")
es_callback = EarlyStopping(
monitor="val_acc", patience=50
) # patience is the number of epochs to wait before early stopping in case of no further improvement
mc_callback = ModelCheckpoint(
"logs/best_model.h5", monitor="val_acc", save_best_only=True, save_weights_only=True
)
Train the model
[17]:
history = model.fit(
train_gen,
epochs=50,
validation_data=val_gen,
verbose=0,
shuffle=False, # this should be False, since shuffling data means shuffling the whole graph
callbacks=[es_callback, mc_callback],
)
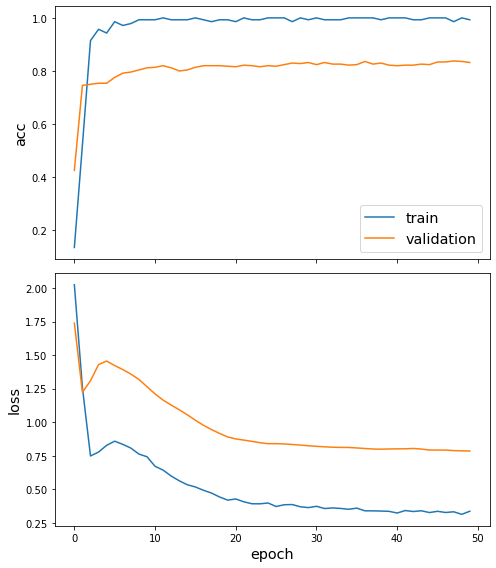
Plot the training history:
[18]:
sg.utils.plot_history(history)
Reload the saved weights of the best model found during the training (according to validation accuracy)
[19]:
model.load_weights("logs/best_model.h5")
Evaluate the best model on the test set
[20]:
test_gen = generator.flow(test_subjects.index, test_targets)
[21]:
test_metrics = model.evaluate(test_gen)
print("\nTest Set Metrics:")
for name, val in zip(model.metrics_names, test_metrics):
print("\t{}: {:0.4f}".format(name, val))
Test Set Metrics:
loss: 0.8700
acc: 0.7863
Making predictions with the model¶
Now let’s get the predictions for all nodes:
Note that the predict function now operates differently to the GraphSAGE or HinSAGE models in that if you give it a set of nodes, it will still return predictions for all nodes in the graph, and in a fixed order defined by the order of nodes in X and A (which is defined by the order of G.nodes()).
[22]:
all_nodes = node_subjects.index
all_gen = generator.flow(all_nodes)
all_predictions = model.predict(all_gen)
Note that for full-batch methods the batch size is 1 and the predictions have shape \((1, N_{nodes}, N_{classes})\) so we we remove the batch dimension to obtain predictions of shape \((N_{nodes}, N_{classes})\).
[23]:
all_predictions = all_predictions.squeeze()
These predictions will be the output of the softmax layer, so to get final categories we’ll use the inverse_transform method of our target attribute specification to turn these values back to the original categories
[24]:
node_predictions = target_encoding.inverse_transform(all_predictions)
Let’s have a look at a few:
[25]:
df = pd.DataFrame({"Predicted": node_predictions, "True": node_subjects})
df.head(20)
[25]:
| Predicted | True | |
|---|---|---|
| 31336 | Probabilistic_Methods | Neural_Networks |
| 1061127 | Rule_Learning | Rule_Learning |
| 1106406 | Reinforcement_Learning | Reinforcement_Learning |
| 13195 | Reinforcement_Learning | Reinforcement_Learning |
| 37879 | Probabilistic_Methods | Probabilistic_Methods |
| 1126012 | Probabilistic_Methods | Probabilistic_Methods |
| 1107140 | Theory | Theory |
| 1102850 | Neural_Networks | Neural_Networks |
| 31349 | Probabilistic_Methods | Neural_Networks |
| 1106418 | Theory | Theory |
| 1123188 | Neural_Networks | Neural_Networks |
| 1128990 | Genetic_Algorithms | Genetic_Algorithms |
| 109323 | Probabilistic_Methods | Probabilistic_Methods |
| 217139 | Theory | Case_Based |
| 31353 | Probabilistic_Methods | Neural_Networks |
| 32083 | Neural_Networks | Neural_Networks |
| 1126029 | Reinforcement_Learning | Reinforcement_Learning |
| 1118017 | Neural_Networks | Neural_Networks |
| 49482 | Neural_Networks | Neural_Networks |
| 753265 | Neural_Networks | Neural_Networks |
Node representations¶
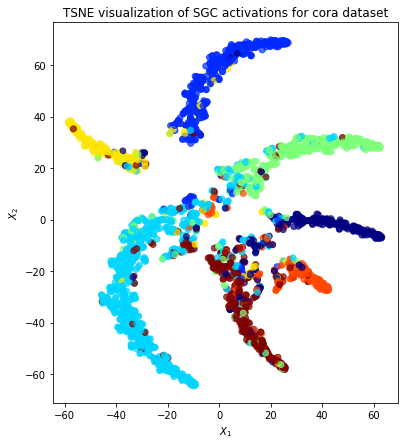
Evaluate node representations as activations of the output layer and visualise them, coloring nodes by their true subject label. We expect to see nice clusters of papers in the node representation space, with papers of the same subject belonging to the same cluster.
We are going to project the node representations to 2d using either TSNE or PCA transform, and visualise them, coloring nodes by their true subject label.
[26]:
X = all_predictions
y = np.argmax(target_encoding.transform(node_subjects), axis=1)
[27]:
if X.shape[1] > 2:
transform = TSNE # PCA
trans = transform(n_components=2)
emb_transformed = pd.DataFrame(trans.fit_transform(X), index=list(G.nodes()))
emb_transformed["label"] = y
else:
emb_transformed = pd.DataFrame(X, index=list(G.nodes()))
emb_transformed = emb_transformed.rename(columns={"0": 0, "1": 1})
emb_transformed["label"] = y
[28]:
alpha = 0.7
fig, ax = plt.subplots(figsize=(7, 7))
ax.scatter(
emb_transformed[0],
emb_transformed[1],
c=emb_transformed["label"].astype("category"),
cmap="jet",
alpha=alpha,
)
ax.set(aspect="equal", xlabel="$X_1$", ylabel="$X_2$")
plt.title(
"{} visualization of SGC activations for cora dataset".format(transform.__name__)
)
plt.show()
Execute this notebook:
![]()
![]() Download locally
Download locally
